


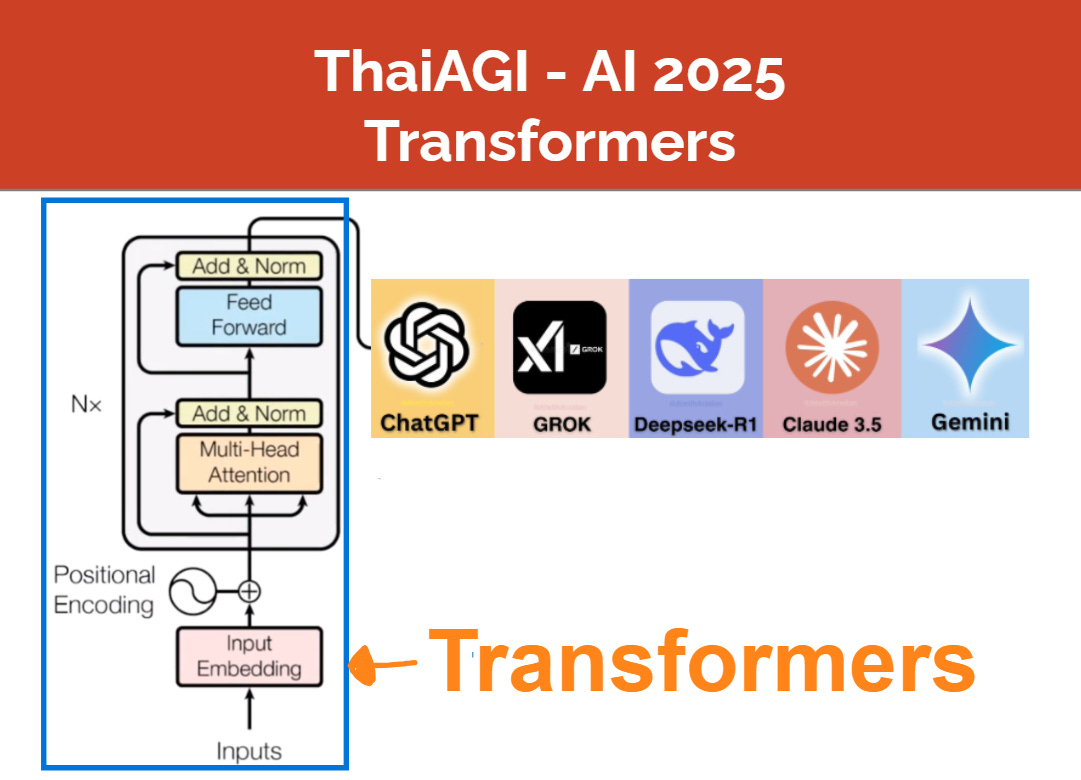
จากบทความ “ปฐมบท AGI” เราได้เห็นแล้วว่า โมเดล AI ที่ปฏิวัติเทคโนโลยีโลกไม่ว่าจะเป็น ChatGPT หรือ Gemini ล้วนมีโมเดลที่ชื่อว่า Transformers เป็น “สมอง” หรือ “ความฉลาด” ตัวจริงของ AI เหล่านี้
GPT ก็ย่อมาจากคำว่า Generative Pretrained Transformers และแท้จริงแล้ว ChatGPT เป็นโมเดลที่อัพเกรดจาก Transformers มาเล็กน้อยเท่านั้น หัวใจสำคัญยังอยู่ที่ Transformers
ใน ThaiAGI Transformers Series เราจะมาทำความรู้จัก Transformers กันอย่างละเอียด โดยบทความนี้เป็นจุดเริ่มต้นของ Series นี้และจะประกอบไปด้วยสี่หัวข้อหลัก ที่เชื่อมโยงกันดังนี้ครับ
(เกือบ)ทุกปัญหาที่ AI แก้ มาจากปัญหาง่ายๆ ที่เรียกว่า “Classification” หรือ “ปัญหาการแบ่งประเภทวัตถุ” ซึ่ง Transformers ก็มาแก้ปัญหานี้เช่นกัน โดยมุมมอง classification นี้สามารถขยายไปสู่ปัญหาการพูดโต้ตอบในภาษามนุษย์ของ ChatBots ทั้งหลายได้
ในปัญหา classification ง่ายๆ AI สมัยก่อน เราใช้
2.1 (ขั้น I) Feature Extraction) “ความรู้มนุษย์” สร้าง Features โดยแต่ละ feature แทนการวัดค่าบางอย่างจากวัตถุ
2.2 (ขั้น II) Linear Model ลากเส้นแบ่งวัตถุแต่ละกลุ่มออกจากกันในวัตถุที่ซับซ้อนเช่น “ภาษามนุษย์” ที่เราต้องการให้ AI เข้าใจ
(ขั้น I*) ตีความหมาย Features ใหม่ โดยใช้การตีความว่า feature คือ “ทิศทางใน vector space”
(ขั้น II*) ตีความหมาย Linear Model ใหม่ เปลี่ยนจากการมองเป็นการลากเส้นแบ่ง เป็นการ “หา vector ในทิศทางที่เหมาะสม”ทำความรู้จัก “ภาพรวม” ของส่วนประกอบหลักในโมเดล Transformers —> Neural networks, Attentionsม Embedding และอื่นๆ ซึ่งจะลิงก์ไปบทความถัดไปของ ThaiAGI Transformers Series ที่จะอธิบายส่วนประกอบทุกชิ้นของ Transformers อย่างละเอียด
1. (เกือบ)ทุกปัญหาของ AI เริ่มจากปัญหาชื่อ Classification
แม้ว่าในบทความปฐมบท AGI เราได้พูดเรื่องนี้ไปบ้างแล้ว แต่ในบทความนี้เราจะลงรายละเอียดกันครับ
ปัญหาจำแนกประเภท (Classification) มีโจทย์คือ “จงพิจารณาวัตถุที่กำหนด แล้วบอกว่าวัตถุนั้นจัดเป็น “ประเภท” (class) ใด”
โดยวัตถุที่กำหนดคือข้อมูลที่เราสนใจจะให้ AI วิเคราะห์ ไม่ว่าจะเป็น รูปภาพ ข้อความ วิดีโอ ฯลฯ ส่วน “ประเภทของวัตถุ” (classes) ทั้งหมด ก็จะถูกกำหนดไว้โดยผู้ตั้งโจทย์นั่นเอง
ตัวอย่างที่เข้าใจง่ายที่สุดคือโจทย์คลาสสิก “จำแนกดอกไม้ตระกูล Iris สาม สายพันธุ์” นั่นคือ Versicolor, Setosa และ Virginica ดั่งรูปที่ 2
โจทย์ Iris Classification : ให้รูปภาพของดอกไม้ (วัตถุที่เราสนใจ) จงพิจารณาว่ารูปนั้นเป็นสายพันธุ์ไหน ?

ปัญหานี้เป็นปัญหาที่นักสถิติระดับปรมาจารย์คือ Sir. Ronald Fisher สนใจมาตั้งแต่ปี 1936 และยังเป็นปัญหาที่ทดสอบมาตรฐานของ AI หรือ Machine Learning ในยุค 1980-1990 อีกด้วย
สังเกตว่าทั้ง 3 สายพันธุ์มีความคล้ายกันมาก (แยกยังไงดีครับ?)
สมัย 1980-1990 เรายังไม่มีโมเดลที่สามารถ “ทำความเข้าใจ” รูปภาพดอกไม้เหล่านี้ได้ด้วยซ้ำ
แต่ Sir. Ronald Fisher ก็ “คิด” วิธีแยกขึ้นมาได้ตั้งแต่เกือบร้อยปีก่อนครับ โดย Sir. Ronald ได้สังเกตพบว่ากลีบดอก (Petal) นั้นเป็นตัวแปรที่สำคัญ
โดยวิธีการคือเราจะ “วัด” ความกว้างและความยาวของ กลีบดอกของแต่ละดอกในฐานข้อมูล ดังแสดงในรูป 3 (ซ้าย)
เช่น สมมติในฐานข้อมูลเรามีตัวอย่างดอกไม้อยู่ 300 ดอก สายพันธุ์ละ 100 ดอก
ตารางในรูป 3 (ซ้าย) ก็จะมีอยู่ 300 แถว แต่ละแถวแทนข้อมูลของแต่ละดอกในฐานข้อมูล
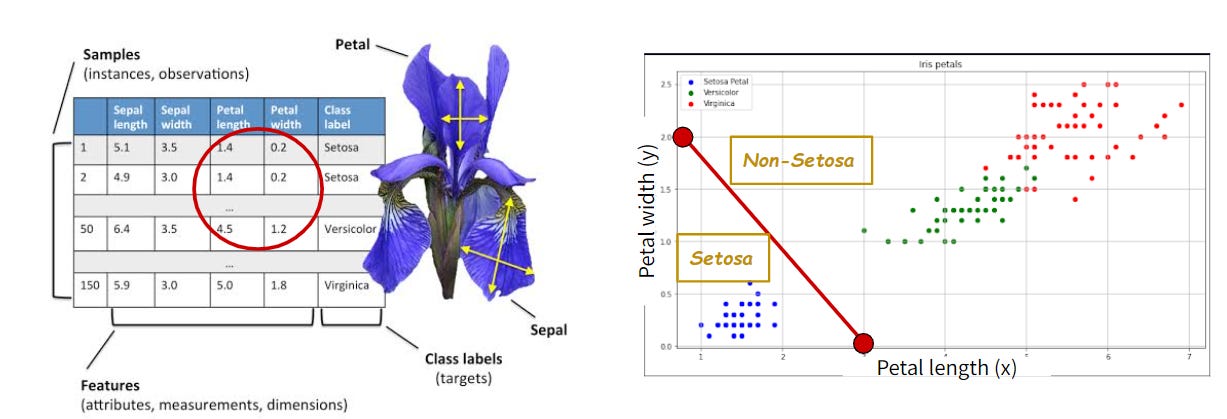
“ความกว้าง” และ “ความยาว” ของกลีบดอกที่มนุษย์วัดตัวเลขมานี้ ถ้าเรามาพลอตในแกน xy ดังรูปที่ 3 (ขวา) สังเกตว่าเราสามารถ “ลากเส้นตรง” แบ่งระหว่าง Setosa กับอีกสองสายพันธุ์ได้ และเราก็สามารถลากเส้นคล้ายๆ กันแบ่งระหว่างอีกสองสายพันธุ์ได้เช่นกัน1
เทคนิคการลากเส้นตรงเพื่อแบ่งข้อมูลในข้อมูล 2 มิติ หรือ “ระนาบตรง” (linear hyperplane) เมื่อข้อมูลมีมากกว่า 2 มิติขึ้นไป (ดู footnote 1) เรียกว่า “Linear Model”2
จากรูปที่ 3 เราใช้ Linear Model “แก้ปัญหา” Classification ของ Iris ได้สำเร็จ (อย่างน้อยก็กับดอกไม้ในฐานข้อมูลของเรา)
ทว่าปัญหา Classification และ Linear Model ที่อธิบายมานี้เกี่ยวข้องกับ AI เช่น ChatGPT หรือ AlphaGo อย่างไร?
คำตอบคือ งาน AI ที่ดูซับซ้อนเหล่านี้ แท้จริงแล้วสามารถมองให้อยู่ในรูป classification ได้ดังแสดงในรูปที่ 4 ครับ
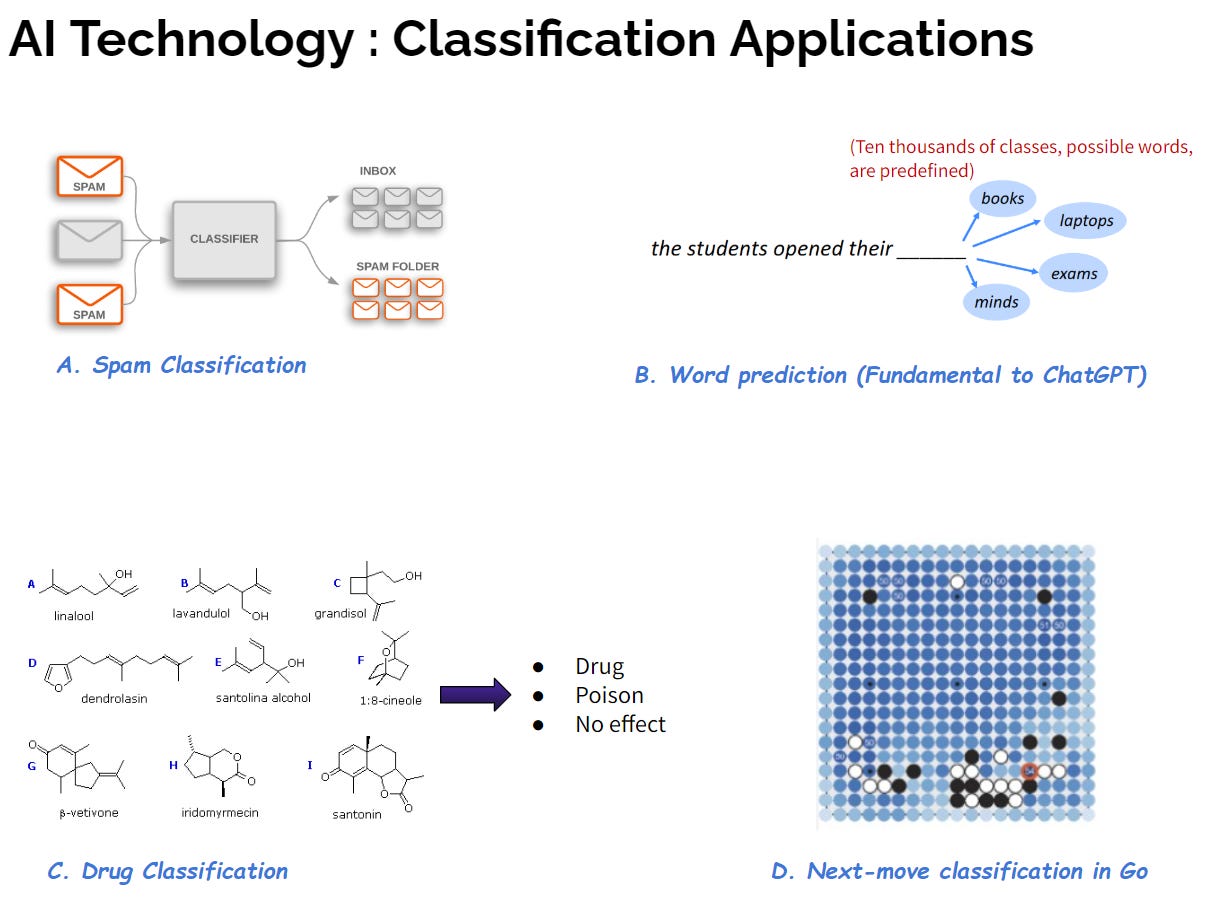
งานของ AI ในตัวอย่าง A. - D. ในรูป 4 ล้วนมีปัญหา Classification เป็นส่วนประกอบสำคัญ
A. งาน AI ในยุคเริ่มต้นคือการ “คัดกรอง email ขยะ หรือ spam” ซึ่ง Google นำมาใช้กับ Gmail ในช่วงทศวรรษ 2000 ซึ่งถือว่าเป็นนวัตกรรมที่นำหน้าคู่แข่งอื่นๆ โดยปัญหานี้เห็นได้ชัดเจนว่าเป็นปัญหา Classification ที่เราต้องการจำแนก “ข้อความ” ใน email ว่า class ใดระหว่าง class1=“spam” หรือ class2=“ปกติ”
ในยุค 2000 ที่ยังไม่มีเทคโนโลยี Transformers ที่เข้าใจภาษามนุษย์ เราสามารถสร้างตารางคล้ายในรูป 3 (ซ้าย) ด้วยไอเดียง่ายๆ โดยการนับ “คำหรือวลีต้องสงสัย” ในข้อความ โดยในแต่ละ column แทน “คำหรือวลีต้องสงสัย” ที่มนุษย์ออกแบบไว้ (ขั้นตอนนี้เรียกว่า Feature Extraction อธิบายด้านล่าง)
ถ้ามีคำต้องสงสัยจำนวนมากพอ (แต่ละคำอาจมีน้ำหนักไม่เท่ากัน) เราอาจจำแนกว่าเป็น spam เป็นต้น
B. งาน “พูดคุย” ด้วยภาษามนุษย์ที่เราโต้ตอบกับ AI ยุคใหม่เช่น ChatGPT ก็ถูกออกแบบให้เป็นงาน Classification เช่นกัน ปัญหานี้เราเล่าละเอียดในหัวข้อที่ 4 ด้านล่าง โดยไอเดียหลักของการ “ทำนายประโยคพูดคุย” นักวิจัย AI มองว่าเป็นการ “ทำนาย คำ ในประโยคทีละคำ” และการ “ทำนายคำ” ก็คือการทำ classification โดยมี classes ทั้งหมดคือคำศัพท์ทั้งหมดที่เป็นไปได้นั่นเอง
C. งานที่สำคัญมากๆ ในยุคปัจจุบันคือการนำ AI มาช่วยออกแบบยา ซึ่งมองเป็นปัญหา classification ได้เช่นกัน ซึ่งโดยข้อมูลที่เราสนใจจะจำแนกคือ โมเลกุลต่างๆ ที่มีความเป็นไปได้ว่าจะเป็นยา และ class เป้าหมายคือ class1=“ยา”, class2= “อันตรายต่อร่างกาย”, class3= “ไม่มีผลกับร่างกาย” เป็นต้น
ความท้าทายในงานนี้ คือเราจะสามารถให้ AI เข้าใจ input ที่เป็นโมเลกุลได้อย่างไร ซึ่งโดยทั่วไปเราจะใช้เทคนิคแปลงข้อมูลโมเลกุลให้อยู่ในรูปของกราฟ ถ้าเพื่อนสนใจสามารถดูตัวอย่างเพิ่มเติมจากลิงก์ ThaiKeras นี้ครับ
D. AlphaGo อีกงานหนึ่งที่ทำให้ AI มีชื่อเสียงกระฉ่อนโลก เนื่องจากเอาชนะตำนานในวงการโกะอย่าง Lee Sedol ได้ ปัญหาการวาง “หมากถัดไป” ของเกมส์โกะก็สามารถมองเป็นปัญหา classification ได้เช่นกัน โดย input ที่ AI ได้รับคือ “กระดานในแต่ละ turn” ส่วน classes ที่ ต้องจำแนกก็คือ “จุดที่สามารถวางหมากได้ทั้งหมด” เป็นต้นครับ
2. Features และ Linear Model สำหรับ Classification
ย้อนกลับมาที่ Iris สังเกตว่าเราได้ “แก้ปัญหา” Iris classification ได้ด้วยขั้นตอนหลัก 2 ขั้นตอน
(I) Feature Extraction : มนุษย์ “คิด” วิธี “การวัด” ตัวเลขอะไรบางอย่างจาก “วัตถุ” ที่กำหนด โดย “ตัวเลขของวัตถุที่ถูกวัด” นี้เรียกว่า “Features”3
(II) Linear Classification : ใน feature space, ใช้ “ระนาบตรง” แบ่งวัตถุคนละกลุ่มออกจากกัน
ซึ่งสองขั้นตอนนี้เป็นหัวใจสำคัญของการแก้ปัญหา Classification แทบทั้งหมด (หัวใจสำคัญของ AI ในอดีต) เราจะมาลองดูตัวอย่างเพิ่มเติมในปัญหา classification ที่มี input เป็น “ข้อความภาษามนุษย์” (text document) เช่น ปัญหาการคัดกรอง email ขยะ กันครับ
บทแทรก: Features คืออะไรกันแน่?
features เป็น concept ที่สำคัญมากๆ ใน AI และ Machine Learning ครับ ทั้งนี้เพราะเราต้องการให้ AI เข้าใจวัตถุต่างๆ ในโลก เราจำเป็นต้องทำให้วัตถุเหล่านั้นอยู่ในรูปที่คอมพิวเตอร์เข้าใจถูกไหมครับ? ซึ่งคอมพิวเตอร์จะเข้าใจข้อมูลตัวเลขได้ดีมาก
ในสมัยอดีตช่วงปี 1950-2000 เทคโนโลยียังไม่เจริญ สมมติเราสนใจรูปภาพของวัตถุต่างๆ หรือข้อความยาวๆ การให้คอมพิวเตอร์ (หรือโมเดล AI) อ่านข้อมูลจากรูปภาพหรือข้อความยาวๆ โดยตรง เป็นเรื่องที่เกินกำลังคอมพิวเตอร์ในสมัยก่อนที่จะทำได้ เราจึงจำเป็นต้องหาวิธีนำเสนอวัตถุเหล่านั้นด้วยตัวเลขต่างๆ ที่วัดจากวัตถุนั้น
เช่นถ้า input เป็นรูปภาพ มนุษย์อาจจะวัด ส่วนสูง ความกว้าง สี น้ำหนัก ฯลฯ ของวัตถุในรูปภาพแล้วส่งตัวเลขเหล่านี้ให้คอมพิวเตอร์แทนรูปภาพจริงๆ คล้ายกับที่เราวัดความกว้างยาวของกลีบดอกในรูปภาพดอกไม้ Iris
หลายๆ features ที่มนุษย์คิดเป็น Boolean (จริง/ไม่จริง ซึ่งแทนด้วยตัวเลข 0/1) เช่น “วัตถุในรูปมีวงกลมเป็นส่วนประกอบหรือไม่?” “มีแว่นตาในรูปหรือไม่?” “มีสิ่งมีชีวิตหรือไม่?” ฯลฯ
สำหรับ input ที่เป็นข้อความ (texts) นั้นในอดีตมนุษย์มักจะคิด features จากการนับคำต่างๆ ในข้อความ โดยหัวข้อ 2.1 ด้านล่างแสดงตัวอย่างของเทคนิคนี้สังเกตว่า features ที่ดีในมุมมองนี้ ต้องอาศัยความคิดสร้างสรรค์และความพยายามจากมนุษย์ เช่น ใน Iris ถ้าเราวัดความกว้างยาวของดอกไม้ตรงๆ ก็จะทำนายสายพันธุ์ไม่ได้ ต้องคิดออกว่าต้องวัดความกว้างยาวของกลีบดอกแทน
จากเราจะนำเสนอตัวเลขของ features ที่วัดได้เหล่านี้ด้วยเวกเตอร์ เพื่อที่จะได้ใช้คณิตศาสตร์ Linear Algebra มาประมวลผลต่อได้ ดั่งแสดงในหัวข้อ 2.2 ด้านล่าง
หมายเหตุ: ใน AI ยุคปัจจุบัน ถึงแม้นว่าเราจะสามารถใส่ รูปภาพ หรือข้อความให้โมเดล AI ได้ตรงๆ โดยมนุษย์ไม่ต้องคิด feature เอง นักวิจัยก็ยังตีความหมาย (รวมทั้งมีการทดลองยืนยันดังเล่าในบทความหน้า) ว่าโมเดล AI สมัยใหม่นั้นมีการ ดึง features ที่มีความหมายลึกซึ้งจาก inputs ออกมาได้เอง
คำว่า “ดึงมาได้เอง” หมายถึง inputs จะผ่านกระบวนการคณิตศาสตร์ของโมเดล AI นั้นๆ เพื่อเปลี่ยนเป็นเวกเตอร์ของ features ที่ดีโดยอัตโนมัติ
(ซึ่งไม่ใช่เวทมนต์ที่ AI เสกขึ้นมา แต่กระบวนการคณิตศาสตร์ของ AI เกิดจากการเรียนรู้จากข้อมูลมหาศาล)
2.1 (I) Feature Extraction
ในขั้น (I) Feature Extraction ของ Iris Classification นั้นสังเกตว่าเราใช้ “ความรู้มนุษย์” เพื่อคิด features 2 ค่าคือ “ความกว้าง” และ “ความยาว” ของกลีบเลี้ยงขึ้นมา ซึ่งกระบวนการใช้ความรู้มนุษย์นี้จะมีประสิทธิภาพในปัญหาเล็กๆ ง่ายๆ
แต่มนุษย์ไม่สามารถนำวิธี Feature Extraction ที่มนุษย์ต้องคิดเองนี้ ไปยังปัญหาที่ซับซ้อนมากๆ เช่นทำความเข้าใจภาษา ทำนายการเดินหมากโกะ หรือทำนายโมเลกุลในรูปที่ 4 ได้
อย่างไรก็ดีเราลองมาดู ความพยายามของ AI ในอดีต ที่พยายามทำความเข้าใจภาษากันครับ ไอเดียง่ายๆ ที่ AI สมัยก่อนใช้ในการสร้าง features จาก text document ก็คือการ “นับคำ” ดั่งแสดงในรูปที่ 5 ครับ
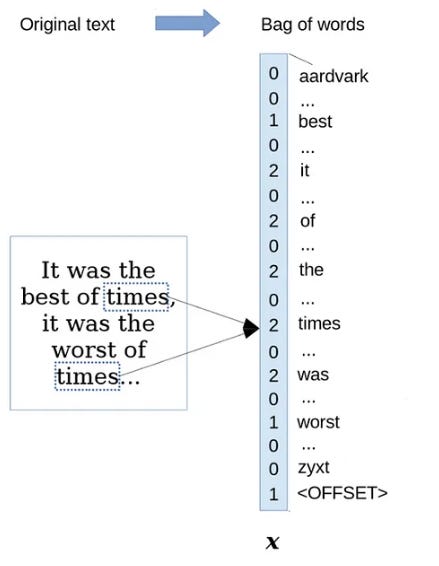
วิธีการสร้าง features ด้วยการนับคำ (bag-of-words) นี้เริ่มจากเรามีลิสต์ของคำศัพท์ทั้งหมดก่อน เช่น สมมติศัพท์ภาษาอังกฤษมี 5,000 คำ เราก็จะสร้าง 5,000 features โดยแต่ละค่าใน feature ก็คือจำนวนครั้งของคำนั้นๆ ที่ปรากฏในข้อความ ดั่งรูปที่ 5
สังเกตว่าเทคนิค bag-of-words นี้ มองว่า “features” ของ text document คือ “คำศัพทฺ์” ทั้งหลาย เทียบกับในปัญหา Iris ที่มองว่า “features” คือความกว้างและยาวของกลีบดอก ซึ่ง สังเกตว่า features ที่มนุษย์คิดขึ้นแบบนี้ส่วนใหญ่จะอธิบายวัตถุที่เราสนใจได้แบบหยาบๆ เท่านั้นและมักจะไปแก้ปัญหา classification ที่ซับซ้อนไม่ได้
อย่างไรก็ดีตอนนี้เราสนใจ features ง่ายๆ แบบนี้ก่อนที่เราจะค่อยๆ พัฒนา features ของ text documents ในหัวข้อและบทความถัดๆ ไป
ในทางคณิตศาสตร์ 5,000 bag-of-words features นี้สามารถแทนด้วย vector x ที่อยู่ใน 5,000-dimensional vector space (ซึ่งการแทน 1 feature ด้วย 1 vector dimension อาจเรียกว่า feature-as-1-dimension ซึ่งเราจะพูดถึงอีกในหัวข้อ 3)
ดังนั้นในปัญหาจำแนกอีเมลขยะ ในรูปที่ 4 เราจะมีข้อมูล input เป็นข้อความใน email ซึ่งจะถูกแทนด้วยเวกเตอร์ x และเป้าหมาก็คือจำแนกเวกเตอร์ x ว่าเป็นประเภทใด (a) อีเมลขยะ (b) อีเมลดี เป็นต้น
จะเห็นว่าเราได้ทำขั้นตอนที่ (I) feature extraction เสร็จสิ้นแล้ว ขั้นตอนถัดไปก็คือ การลากเส้นแบ่งโดยใช้ Linear Model คล้ายกับในปัญหา Iris Classification ในรูปที่ 3
2.2 (II) Linear Model
ถัดมา สมมติว่าเราทำขั้นตอนที่ (I) ได้ นั่นคือเรามีวิธีในการสร้าง features ได้ (ถึงแม้ว่าแท้จริงแล้ว feature ที่ได้จากวิธี bag-of-words โดยตรงจะไม่ดีเท่าไรนัก) เราก็จะมาต่อกันที่ขั้นตอน (II) คือ Linear Classification
ย้อนกลับไปในภาพที่ 3 ในปัญหา Iris Classification ซึ่งเราสนใจเพียงแค่ 2 features คือความกว้างและความยาวของกลีบดอกไม้ เราจึงสามารถนำ 2 features นี้มาพล็อตในแกน x-y และลากเส้นแบ่งได้ ทว่าในปัญหาจำแนก email นี้เรามีถึง 5,000 features แล้วเราจะลากเส้นแบ่งอย่างไร !?
…
แท้จริงแล้วเราจะมี 5,000 features ก็ไม่เป็นปัญหาอะไร เพราะคณิตศาสตร์ที่ชื่อ Linear Algebra ได้คิดและแก้ปัญหาไว้หมดแล้ว ด้วยการคูณเมตริกซ์และเวกเตอร์เพียงครั้งเดียว
โดยใน high-dimensional vector space การแบ่งครึ่งจะทำด้วยระนาบตรง (hyperplane) โดยในรูป 6 แสดงภาพใน 3 มิติ แต่ไม่ว่าจะกี่มิติ เราก็ใช้การคูณเมตริกซ์และเวกเตอร์หนึ่งครั้งเหมือนกัน

โดยทั่วไปสมมติวัตถุที่เราต้องการจะทำ Classification นั้นมี features ทั้งหมดจำนวน D features และประเภทของวัตถุนั้นมี C ประเภท (class-1, class-2, .., class-C)
การแทนตัวแปร D และ C นี้ทำให้เรามองปัญหา linear classification ทั้งหมดให้อยู่ในรูปเดียวกัน เช่น ในปัญหา Iris นั้น D=2, C=3 และในปัญหา email ด้านบน D=5000 , C=2 เป็นต้น ซึ่งไม่ว่า D และ C นี้จะมีค่าเท่าไร เราก็ใช้คณิตศาสตร์สมการเดียวกันในการแก้ปัญหา
ในการทำ Linear Classification บนปัญหานี้ ก่อนอื่นเราแทน features ได้ด้วยเวกเตอร์ใน D-dimensional space ดังนี้ (หลังจากทำ feature extraction แล้ว)
การจำแนกวัตถุว่าเป็นประเภทใดใน C classes ด้วย Linear Model บน D-dimensional space นั้นจะถูกกำหนดด้วยเมตริกซ์ A ขนาด C x D และเวกเตอร์ b ตามสมการนี้
โดยเวกเตอร์ b และ เวกเตอร์ผลลัพธ์ y จะเป็นเวกเตอร์ใน C-dimensional space
ซึ่งเราสามารถแปลความหมายเวกเตอร์ y ได้ว่าเป็น score ของแต่ละ class
การทำนายว่าเป็น class ใดเราก็เพียงแต่ดูว่าตำแหน่งใดใน 1 ถึง C ของเวกเตอร์ y ที่มี score มากที่สุด เราก็ทำนายว่าเป็น class นั้นไป
เช่น “สมมติ” เราทราบ A และ b ที่สามารถคำนวน score ได้แม่นยำ และ C=5 และเราคำนวนได้
y = Ax + b = (-5, 2, 100, 88, -99)
จะเห็นว่าตำแหน่งที่ 3 มี score มากที่สุดเท่ากับ 100 คะแนนเราก็ทำนายว่า x เป็น class ที่ 3 เป็นต้น
ซึ่งหัวใจของการทำนายด้วย Linear Model นี้เราต้องทราบ A และ b ที่คำนวน score ได้แม่น ซึ่งการที่จะทราบ A และ b ที่ดีนั้นเราจะมีวิธี “เรียนรู้” จากข้อมูล (Machine Learning) ซึ่งเป็นอีกเรื่องใหญ่ที่จะพูดถึงในบทความอนาคต4
ส่วนในบทความนี้เราสมมติว่า A และ b นั้นได้ถูกเรียนรู้จากข้อมูลมาเรียบร้อยแล้ว
ดังนั้นสังเกตว่าในมุมมองนี้ปัญหา classification สามารถแก้ได้ด้วยการคูณเมตริกซ์ Ax ครั้งเดียว (แล้วบวกด้วย b) ก็สามารถแก้ปัญหาได้เลย ทว่าคณิตศาสตร์เบื้องหลัง AI มันง่ายอย่างนี้จริงหรือ?
3. มุมมองใหม่ของ Features และ Linear Model ใน Transformers
จุดอ่อนสำคัญของการนำเทคนิค bag-of-words มารวมกับ linear classification ตรงๆ ก็คือ โมเดลจะไม่สามารถทำความเข้าใจข้อความที่ซับซ้อนได้ เช่น สมัยก่อนการพยายามจำแนกประเภท email ขยะ ก็จะขึ้นอยู่กับ “คำอันตราย” บางคำ เช่นคำว่า “โอนเงิน”
นั่นคือ สมมติโมเดล AI สมัยก่อนที่ทำ bag-of-words + linear classification ถ้าเห็นเวกเตอร์มี feature “โอนเงิน” > 0 (หรือตัวเลขอื่น) ก็อาจจะสรุปว่าเป็น email ขยะทันที ซึ่งการจำแนกแบบนี้จะพบเห็นความผิดพลาดบ่อยครั้ง
ทั้งที่จริงแล้วมนุษย์เราจำเป็นต้องอ่านข้อความทั้งหมด และ “ทำความเข้าใจ” ถึงจะสรุปได้ว่าเป็นอีเมลขยะหรือไม่ การกระทำเพียง “นับคำ” นั้นไม่อาจเทียบเท่า “การทำความเข้าใจ” ของมนุษย์ได้เลย
ChatGPT หรือ Transformers นั้นมีการสร้าง Features จากข้อความด้วยเทคนิคที่พิศดารพันลึก (ดูภาพรวมในหัวข้อถัดไป) ทว่าในพื้นฐานที่สุดนั้น ก็อยู่ยังบน Linear Model ซึ่งเราต้องเริ่มจากการเปลี่ยนมุมมองของ “feature” ใหม่เสียก่อน
(a) เปลี่ยนจากมุมมอง “feature as 1-dimension” (เดิม ใช้ใน bag-of-words) มาเป็น “feature as direction” (ใหม่)
(b) เปลี่ยนมุมมอง “linear model” จากมองเป็นการ “ลากเส้น/ระนาบ แบ่ง” (เดิม) เป็น “การหาทิศทางที่เหมาะสม” (ใหม่)
เราจะเริ่มกันทีละจุดครับ ภาพที่ 7 แสดงตัวอย่าง “feature as 1-dimension” vs. “feature as direction”
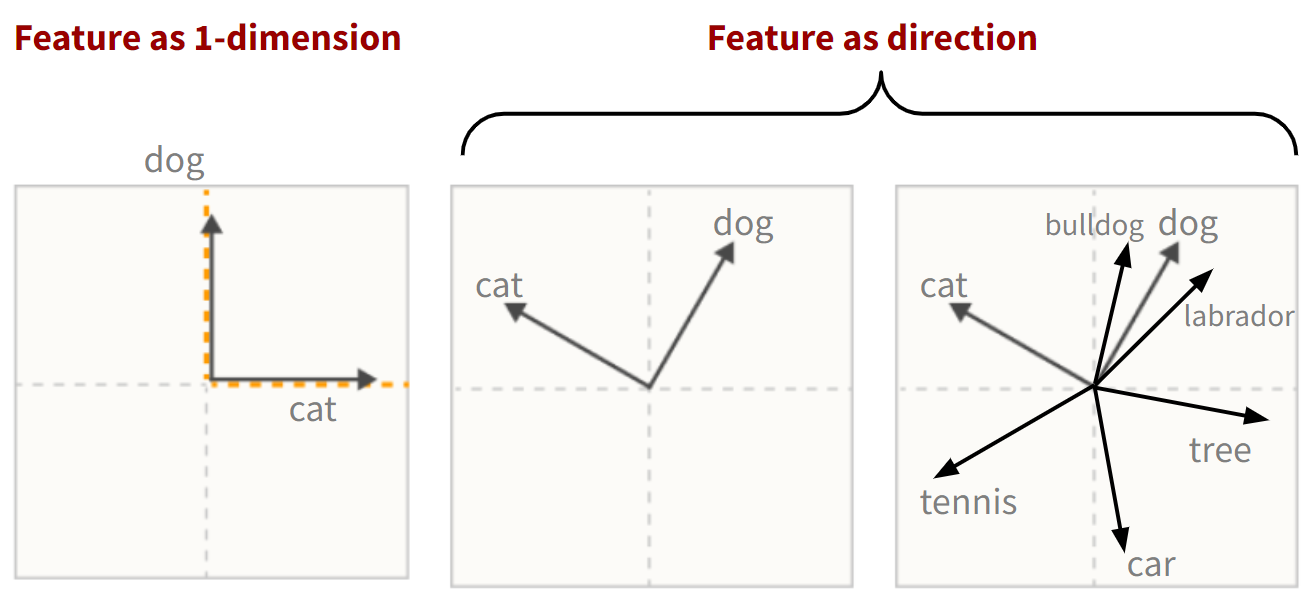
เพื่อให้เข้าใจง่ายๆ เราจะใช้หลักการ bag-of-words (รูปที่ 5) ในโลกสมมติที่คำศัพท์ในโลกมีแค่ 7 คำคือ dog, cat, tennis, car, tree, bulldog และ labrador และสมมติเราต้องการพิจารณาทำ classification บน text document ที่มีข้อความว่า
dog cat cat labradorด้วยเทคนิค bag-of-words เราจะเปลี่ยน document นี้ได้เป็นเวกเตอร์ 7 มิติ (เพราะมีศัพท์ 7 คำ) ดังนี้
(1, 2, 0, 0, 0, 0, 1) # แปลว่า 1-dog, 2-cats, 1-labrador
=
(1, 0, 0, 0, 0, 0, 0) + # 1-dog
(0, 2, 0, 0, 0, 0, 0) + # 2-cats
(0, 0, 0, 0, 0, 0, 1) # 1-labradorสังเกตว่าในมุมมองของ bag-of-words ศัพท์สองคำ หรือ 2 features เช่น dog กับ cat จะอยู่คนละมิติหรือคนละแกน ใน 7-dimensional vector space ดังรูปที่ 7 (ซ้าย - แสดงแค่ 2 มิติแรก)
การที่ feature หนึ่งๆ (ในที่นี่ features ของ text document คือคำศัพท์ต่างๆ) แสดงด้วยตัวเลขในมิติหนึ่งเดียวใน vector space เราขอเรียกว่า “feature as 1-dimension”
ด้วยหลักการ “feature as 1-dimension” นี้ ถ้าเรามี D features, เราจะต้องแทนด้วยเวกเตอร์ใน D-dimensions ซึ่งมีข้อเสียหลักอยู่สองอย่างครับ
“ต้องการหน่วยความจำ (memory) มหาศาล” โมเดลระดับ ChatGPT ที่จำศัพท์ของทุกภาษาทั่วโลกนั้นมีคำศัพท์พื้นฐานอยู่หลายแสนคำ ดังนั้นถ้าเราใช้หลักการ “feature as 1-dimension” เราจะต้องทำงานบน หลายแสน-dimensional vector space ซึ่งแค่คูณเมตริกซ์ใน vector space นี้ก็ต้องการหน่วยความจำในการคำนวนมหาศาล ซึ่งไม่เหมาะสมในทางปฏิบัติ และโมเดลอย่าง ChatGPT หรือ Transformers เองก็ต้องคูณเมตริกซ์ “หลายล้านครั้ง”
“ไม่สามารถบอกความสัมพันธ์ระหว่างคำได้” แท้จริงแล้วคำศัพท์หรือ feature หลายคำมีความหมายใกล้เคียงกัน เช่น “dog” กับ “bulldog” (พันธุ์ของสุนัข) ดังนั้น เวกเตอร์ที่แทนสองคำนี้ควรจะมีลักษณะใกล้เคียงกันด้วย
ซึ่งในทางคณิตศาสตร์เราคำนวน “ความคล้าย” ด้วย dot-product โดยสองคำที่คล้ายกันควรจะ dot กันได้ค่าบวก แต่ใน bag-of-words ในรูปที่ 7 (ซ้าย) นั้นทุกๆ feature ตั้งฉากกันหมด ดังนั้น features 2 คำใดๆ จึงมีผล dot-product เท่ากับ 0 ทั้งหมด
Feature as Direction หรือ Feature แทนทิศทาง
แนวคิด feature as direction มาจากงานของ Anthropic ตีพิมพ์ครั้งแรกในปี 2022 และงานต่อเนื่องจากนั้นอีกมากมายที่ทำให้เราเข้าใจถึง features ที่ซ่อนอยู่ใน transformers
เราจะค่อยๆ เล่างานเหล่านี้ในแต่ละบทความของ ThaiAGI ครับ
เบื้องต้นสังเกตว่าในทางคณิตศาสตร์ ถ้าเราหมุน feature vector ต่างๆ ไปด้วยองศาเท่าๆ กัน (รูป 7 กลาง) ความสัมพันธ์ต่างๆ ระหว่าง feature vectors เหล่านี้ก็จะยังคงเดิม นั่นคือทุกๆ features ยังตั้งฉากกันอยู่
ในทางคณิตศาสตร์ การหมุนเวกเตอร์ทั้งหมดในองศาเท่าๆ กัน ไม่ได้ทำให้คุณสมบัติต่างๆ เปลี่ยนไปแต่อย่างใด ทว่าทำให้ features สามารถมีอิสระจะหันไปใน “ทิศทาง” ใดก็ได้
สังเกตว่าในรูปที่ 7 (กลาง), features dog และ cat จะมีค่ามากกว่า 0 ในสองมิติ เช่น dog แทนด้วย (0.5, 0.87, 0, 0, 0, 0, 0) ส่วน cat แทนด้วย (-0.87, 0.5, 0, 0, 0, 0, 0) และทั้งสองเวกเตอร์ยังตั้งฉากกันเหมือนเดิม
ซึ่งถ้าเรานำความคิด “ทิศทาง” นี้มาขยายเพิ่มเติม เราสามารถกำหนดให้สองคำที่มีความหมายใกล้เคียงกัน เช่น dog และ bulldog มีทิศทางใกล้ๆ กันได้ (รูปที่ 7 ขวา) ซึ่งยังแปลว่าเรายังอนุญาตให้ feature vectors ต่างๆ “เบียด” กันในแต่ละมิติด้วย
ไอเดียนี้เรียกว่า “feature-as-direction”
รูปที่ 7 (ขวา) แสดงตัวอย่าง dog, bulldog รวมทั้ง labrador ที่มีความหมายใกล้กันจึงแทนด้วย feature vector ที่มีทิศใกล้กัน (ค่า dot product จะสูง) ส่วนสองคำอื่นๆ เช่น cat และ tennis ที่มีความหมายต่างกันจะยัง “เกือบ” ตั้งฉากกันอยู่เช่นเดิม
นอกจากนี้สังเกตุว่าไอเดีย “feature as direction” นี้อนุญาตให้เราบีบอัดคำศัพท์ทั้ง 7 คำมาอยู่ใน 2 มิติ แทนที่จะใช้ 7 มิติ ทำให้ประหยัดเนื้อที่ได้ ทำให้แก้ข้อเสียของ “feature-as-dimension” ทั้งสองข้อได้5
ไอเดียนี้ทำให้ “คำ” ในทางภาษาศาสตร์ ทดแทนด้วย “เวกเตอร์” ในคณิตศาสตร์ได้อย่างลงตัว และเป็นหนึ่งในไอเดียสำคัญที่ ChatGPT / Transformers ใช้ในการเข้าใจ Text Document ภาษามนุษย์
ทบทวนแนวคิดสำคัญ: feature-as-direction ทำให้เราบีบ “ความรู้” ในรูปเวกเตอร์ในปริมาณที่มากกว่า จำนวนมิติ ได้ (เช่น ความรู้ 7 ชนิด ใน 2 มิติ ในรูปที่ 7 ขวา) ในขณะที่แนวคิด feature-as-dimension แบบดั้งเดิม (รูป 7 ซ้าย) จะอนุญาตให้เราเก็บจำนวนความรู้ได้ไม่เกินจำนวนมิติ
Linear Model คือการหา “ทิศทาง” ที่เหมาะสม
ในบทความนี้เราได้เน้นถึงหัวใจสำคัญของ Linear Model ในการแก้ปัญหา Classification ซึ่งในอดีต เราจะแปลความหมาย Linear Model หรือสมการ y = Ax +b เป็นการลากเส้น หรือระนาบแบ่งข้อมูลออกเป็นสองส่วน ดังที่แสดงในรูปที่ 3 และรูปที่ 6
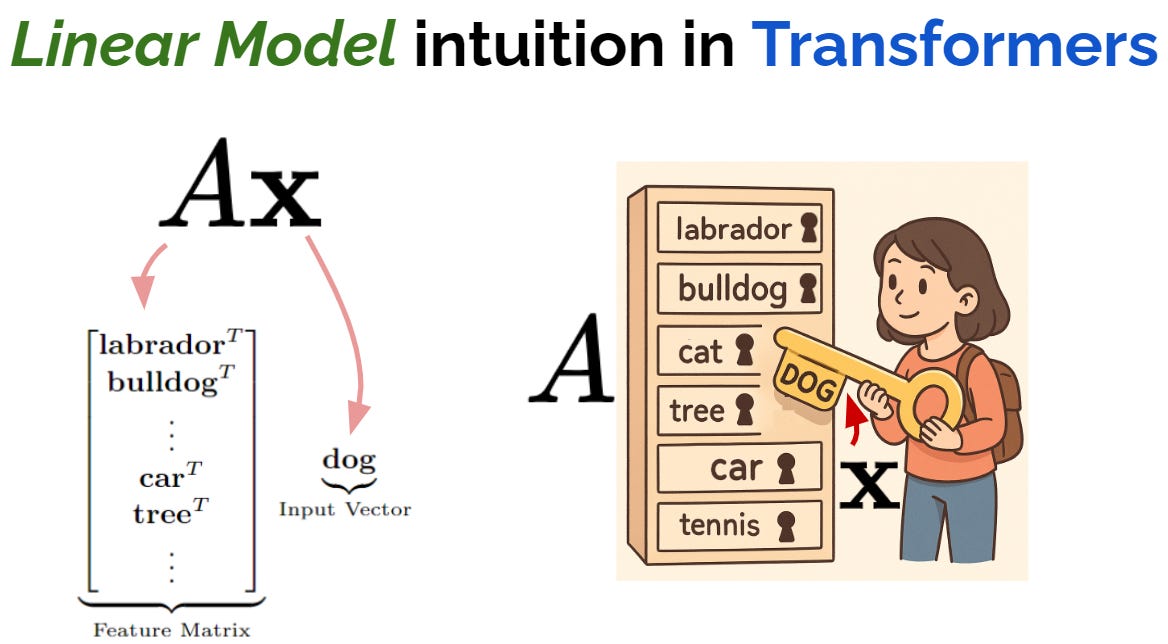
ทว่าใน ChatGPT / Transformers นั้นเราจะเข้าใจการคูณ matrix ได้ดีขึ้นมากถ้าเรามองในไอเดียของ Feature as Direction โดยเริ่มจากการมอง แต่ละแถวเมตริกซ์ของเมตริกซ์ A เป็น feature6 ดังแสดงในรูปที่ 8 (ซ้าย) และสมมติว่าเวกเตอร์ input x คือเวกเตอร์ที่แทน feature “dog”7
การคูณ matrix ด้วยไอเดียนี้ เสมือนมี x เป็นกุญแจ และเราพยายาม “ไขรูกุญแจ” ของแต่ละแถวใน matrix ว่ากุญแจสามารถไขได้ดีแค่ไหน ดั่งแสดงในรูปที่ 8 (ขวา)
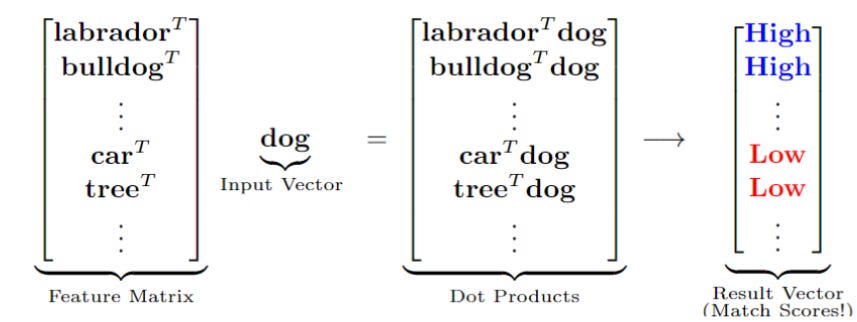
ซึ่งการไขกุญแจ Ax นี้แสดงรายละเอียดในรูปที่ 9 (โดยเราจะยังไม่สนใจค่า b ใน linear model ตอนนี้และจะพูดในรายละเอียดในบทความหน้า)
ในตัวอย่างรูปที่ 9 เมื่อ input vector x = dog, และสองแถวแรกของ A คือ labrador และ bulldog จะเห็นว่าเนื่องจากสอง features นี้มีความใกล้เคียง dog ผลลัพธ์ dot-product จึงมีค่าสูง ในขณะที่แถวอื่นๆ ถ้าเป็น features ที่เกี่ยวข้องน้อยเช่น car หรือ tree ผลลัพธ์ dot-product ก็จะมีค่าต่ำเป็นต้น
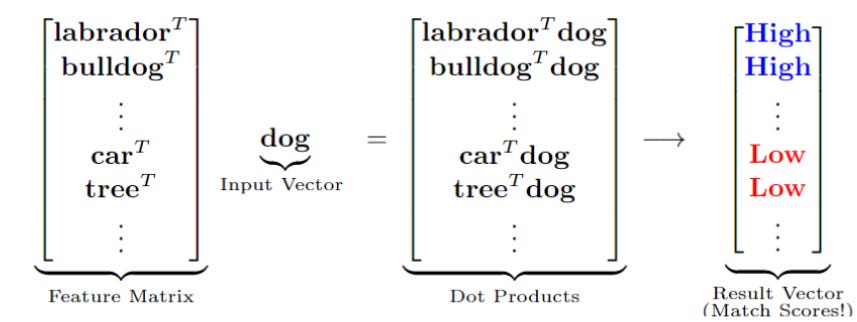
รูปที่ 9 การคูณ matrix ด้วยไอเดีย row-wise multiplication ทำให้ได้ผลลัพธ์ว่าทิศทางใดบ้างในแต่ละแถวที่ตรงกับทิศทางของ input vector ดังนั้น การคูณ Ax ในมุมมองนี้ (row-wise) จึงเสมือนเป็นการหาทิศที่เหมาะสมในแต่ละแถวของ A ถ้าแถวใดมีทิศที่เหมาะสม ก็จะได้ผลลัพธ์การคูณที่มีค่าสูง ซึ่งการแปลความหมายนี้ เราจะมาพูดถึงอีกครั้งในบทความหน้า
จริงๆ แล้วการคูณ Ax ยังแปลความหมาย column-wise ได้ด้วย ซึ่งสำคัญกับการทำความเข้าใจโดยรวมของ ChatGPT และ Transformers เป็นอย่างมากเช่นกัน
เพราะว่าใน Transformers มีองค์ประกอบที่เรียกว่า FFN (ดูหัวข้อด้านล่าง) ที่เป็น “หน่วยความจำหลัก” ของ Transformers (ซึ่งก็คือหน่วยความจำหลักของ ChatGPT หรือระบบ AI ทั้งหมดอีกด้วย)โดย FFN นี้คือ Linear Models 2 ตัวมาเชื่อมต่อกัน8 (คูณเมตริกซ์สองรอบ) โดยถ้าเราแปลความหมาย row-wise ในการคูณครั้งแรก และ column-wise ในการคูณครั้งที่สอง เราจะเข้าใจ “แก่นการเก็บความจำของ Transformers” ได้อย่างง่ายดาย ซึ่งเราจะคุยเรื่องนี้อย่างละเอียดที่สุดในบทความหน้า ซึ่งเป็นเรื่องของ FFN โดยเฉพาะครับ
4. ส่วนประกอบของ Transformers
4.1 เป้าหมายของ Transformers (ทายคำถัดไป) คือ classification
ทบทวนจากรูปที่ 4 ว่า โมเดล AI อย่าง ChatGPT (ที่มี Transformers เป็นสมอง) ที่คุยโต้ตอบกับเราในภาษามนุษย์ได้นั้น มองปัญหาการ “สร้างประโยค” เป็นการทำนาย “คำถัดไป ทีละคำ” (Next-Word Prediction/Classification9) ดั่งโชวรายละเอียดมากขึ้นในรูปที่ 10 ครับ
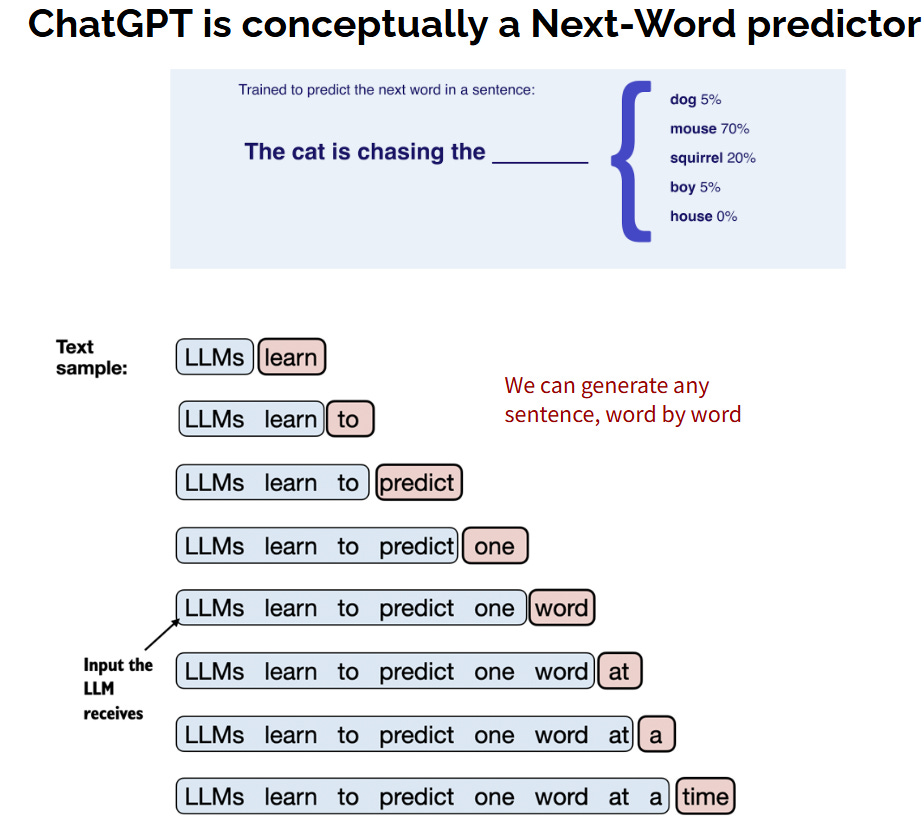
ดังนั้นจากรูป 10 ผู้อ่านจะเห็นได้ว่าในการสร้างประโยคพูดคุยนั้น ท้ายที่สุด Transformers / ChatGPT ก็มาแก้ปัญหา Classification อยู่ดีนั่นเอง (จำแนกประเภท “คำถัดไป” ให้ถูกต้อง)
สังเกตว่าในการสร้าง 1 ประโยคมีการทำนายคำ “หลายครั้ง” ทีละคำ แสดงว่าต้องทำ classification หลายรอบ เช่น ตัวอย่างในรูปที่ 10 (ล่าง) ประโยค “LLMs learn to predict one word at a time” มี 9 คำ แสดงว่า Transformers จะต้องแก้ปัญหา Classification 9 รอบ เพื่อสร้างประโยคนี้ เป็นต้น10
ดังนั้น นับจากจุดนี้ เราจะพิจารณาโมเดล ChatGPT/Transformers ในปัญหา Next-Word Classification เท่านั้น เช่น สมมติว่าประโยค Input คือ “LLMs learn to” ซึ่งประกอบไปด้วย 3 คำ และ ChatGPT/Transformers จะต้องทำนายคำที่ 4 เช่น “Predict” หรือคำอื่นๆ ที่ความหมายใกล้เคียง เป็นต้น
เมื่อเราเข้าใจว่าปัญหาการ Chat ก็คือปัญหา Classification … ดังนั้น “เรื่องสำคัญ” ที่เราต้องตระหนัก ก็จะเหมือนที่เราอธิบายไปในหัวข้อ 2 และ 3 ของบทความนี้ นั่นคือ Transformers จะต้อง (I) ทำกระบวนการ feature extraction จากประโยค Input เพื่อทำนายคำถัดไป โดยใช้ไอเดีย feature as direction เหมือนที่อธิบายไปแล้ว และ (II) สร้าง model ใน feature space เพื่อทำนายคำถัดไปที่เหมาะสม โดยยังมี linear model เป็นส่วนประกอบที่สำคัญมากๆ
ซึ่ง Transformers ออกแบบกระบวนการ (I) และ (II) นี้ โดยการแบ่งออกเป็นหลายโมดูลย่อย หรือเป็นบล็อก (block) ดั่งแสดงในรูปที่ 11 (บน: diagram, ล่าง: pseudo-code) โดยแต่ละบล็อกจะแก้ปัญหาทีละขั้นแล้วส่งต่อไปยังบล็อกถัดไป
4.2 Transformers ประกอบไปด้วยหลายบล็อก
โดยบล็อกหลักๆ คือ A, B, C และ D ส่วนบล็อก E ต่างๆ จะเป็นบล็อกเสริมครับ เราจะต้องเข้าใจบล็อกหลักให้ถ่องแท้ก่อนที่จะไปพิจารณาบล็อกเสริมต่างๆ ครับ
ในภาพที่ 11 เรามองง่ายๆ แบบนี้ครับ
เปลี่ยน Input ภาษามนุษย์ให้เป็น vectors ในขั้นแรกที่เรียกว่า embedding / encoding (A และ B)
จากนั้นก็ process ผ่านบล็อกต่างๆ เพื่อให้ได้ feature vectors ที่ทดแทนภาษามนุษย์ได้ดีที่สุด (C และ D — โดยทำขั้นนี้หลายรอบ)
ก่อนที่จะเข้า linear model บล็อกสุดท้ายที่ชื่อ SoftMax (E2) เพื่อทำ classification ทำนาย “คำถัดไป” ที่จะตอบทีละคำ จนได้เป็นประโยค11
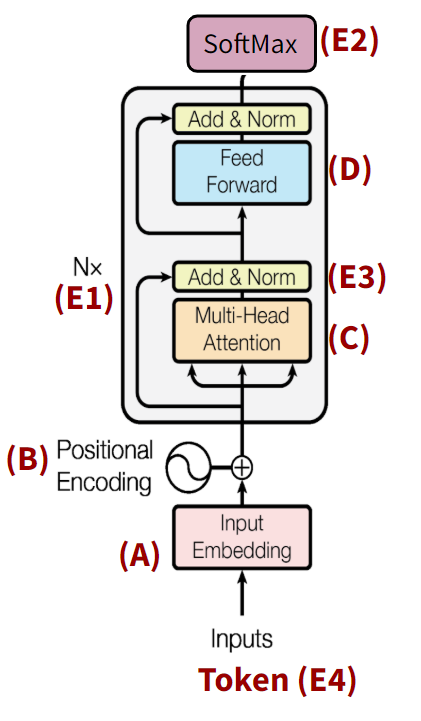

แต่ละบล็อกจะมีบทความเป็นของตัวเอง ซึ่งถ้าผู้อ่านเข้าใจภาพรวมแล้วแล้ว สามารถกดเข้าไปศึกษาบล็อกใดก่อนก็ได้ครับ
Inputs : หมายถึง “คำทุกคำ” ในประโยคก่อนที่จะทำนาย “คำถัดไป” (ส่วนที่แรเงาสีน้ำเงินในตัวอย่างรูป 10) ซึ่ง Transformers ต้องสร้าง features จากคำทั้งหมดใน Inputs เพื่อทำนายคำถัดไป เช่น Input คือ “LLMs learn to” ซึ่งคือประโยคที่มี 3 คำ เป็นต้น12
(A) Input Embedding (บทความแยก กดเลยครับ) : เป็นขั้นแรกของการสร้าง Features, โดยในขั้นนี้จะเปลี่ยน “คำแต่ละคำ” ให้เป็นเวกเตอร์บน D-dimensional space ด้วยไอเดีย feature-as-direction ที่เราอธิบายในหัวข้อก่อน (อย่างไรก็ดีไอเดียนี้มักถูกเรียกว่า “Input/Word Embedding” เพราะสื่อถึงการเปลี่ยน (embed) คำ ให้เป็น เวกเตอร์ นั่นเอง)
เช่น Input คือ “LLMs learn to” เมื่อผ่านขั้น Word Embedding เราก็จะได้เวกเตอร์ 3 เวกเตอร์ คือเวกเตอร์ของ “LLMs”, “learn” และ “to” เมื่อเป็นเวกเตอร์แล้ว ทำให้ AI สามารถเริ่มใช้กระบวนการทางคณิตศาสตร์มาจัดการปัญหา classification ได้ในบล็อกถัดๆ ไป
รายละเอียดในขั้นนี้กดดูได้ที่บทความแยกครับ(B) Positional Encoding หรือ Position Embedding (บทความแยก อยู่ในระหว่างการเขียน) :
เนื่องจากคำแต่ละคำมีตำแหน่งในประโยคที่ต่างกัน ประโยค “LLMs learn to” จึงไม่เหมือนกับ “to learn LLMs” แม้นจะมีคำเดียวกันทั้งหมดในสองประโยคก็ตามTransformers จึงคิดวิธีในการเปลี่ยน “ตัวเลขตำแหน่ง” ให้เป็นเวกเตอร์ด้วย จึงเป็นที่มาของบล็อก Positional Embedding หรือ Positional Encoding นี้
ในทางปฏิบัติ Word Embedding และ Position Embedding จะทำในขั้นเดียวกัน จากนั้นนำเวกเตอร์ผลลัพธ์ของทั้งสองกระบวนการรวมกันเป็นเวกเตอร์เดียว ดังนั้นถ้า Inputs มี N คำ พอสิ้นสุดกระบวนการนี้เราก็จะได้ N เวกเตอร์ เป็นต้น
เช่น Input คือ “LLMs learn to” ถ้าทำทั้งสองขั้น เราจะได้ 3 เวกเตอร์ คือเวกเตอร์ที่แทนความหมายของ (LLMs, ตำแหน่ง-0), (learn, ตำแหน่ง-1) และ (to, ตำแหน่ง-2)
ส่วน “to learn LLMs” เราจะได้ (to, ตำแหน่ง-0), (learn, ตำแหน่ง-1) และ (LLMs, ตำแหน่ง-2) ทำให้สองประโยค Inputs นี้มีการแปลงเป็นเวกเตอร์ที่แตกต่างกัน(C) (Multi-Head) Attention (บทความแยก กดได้เลยครับ) :
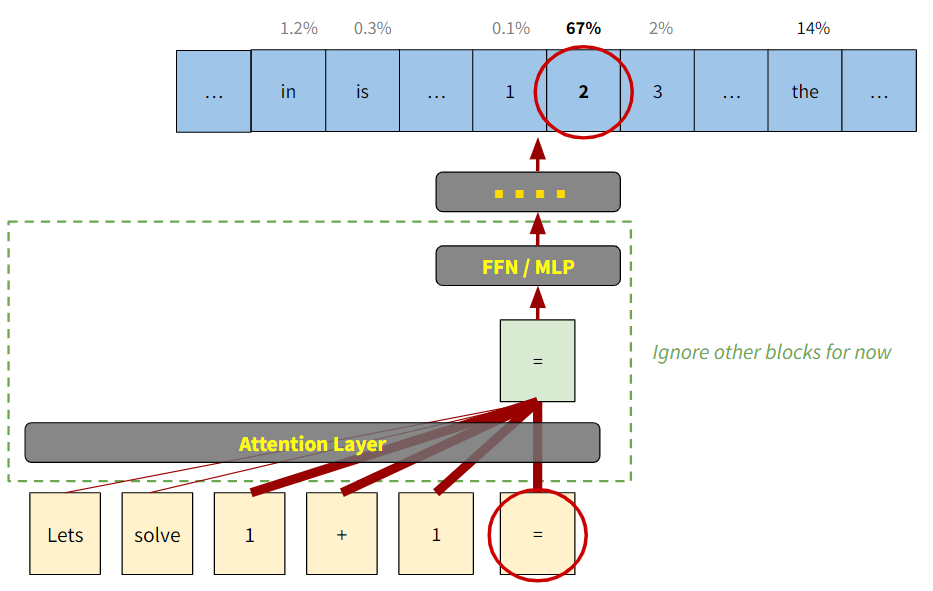
Transformers ถูกออกแบบให้ทำนาย “คำถัดไป” จากเวกเตอร์ของคำสุดท้ายในประโยคเท่านั้น
เช่น ถ้าต้องการทำนายคำถัดไปจาก “Lets solve 1 + 1 =”, คำถัดไปจะถูกทำนายจากเวกเตอร์ของคำสุดท้ายคือ “=” เท่านั้น13 ดังแสดงในรูปที่ 12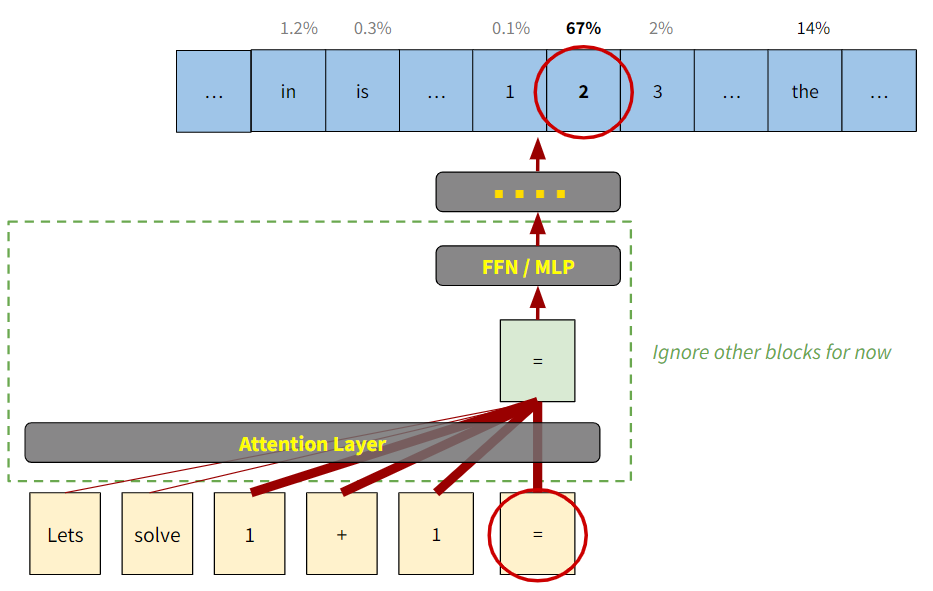
รูป 12 ไอเดียคร่าวๆ ของ Attention Block ในตัวอย่าง “Let solve 1+1 =” ความหนาของเส้นแสดงถึงปริมาณ information ที่ถูกดึงมารวมเพื่อให้ได้เวกเตอร์ output ใหม่ ซึ่งแน่นอน คำถัดไป (ซึ่งควรจะเป็นเวกเตอร์ “2” ) ไม่สามารถทำนายได้จาก information ใน “=” เท่านั้น เราต้องรวม information ของ “1 + 1” เข้ามาด้วย ในขณะที่ information ของ “Lets solve” ไม่จำเป็นเท่าใดนัก
ดังนั้นสิ่งที่ Attention ทำดังแสดงในรูปที่ 12 ก็คือดึง information จาก “1+1” มาใส่ใน “=” และพยายามไม่ดึง information จาก “Lets solve” มารวม ซึ่งกระบวนการมหัศจรรย์นี้ (รู้ได้อย่างไรว่าคำไหนควรรวมหรือไม่ควรรวม) สามารถทำได้อย่างอัตโนมัติเพราะ AI ต้องผ่านการเรียนรู้จากข้อมูลมหาศาลมาก่อน (ดูบล็อก (F) ในสรุปด้านล่าง)
และ output ของ Attention ในขั้นนี้ก็คือเวกเตอร์ “=” ฉบับปรับปรุงใหม่ ดั่งแสดงในบล็อกเขียวในรูปที่ 12 ซึ่งจะไม่เหมือนกับเวกเตอร์ “=” ก่อนที่จะเข้าสู่กระบวนการ Attentionหัวใจของบล็อก (C) Attention ก็คือการรวม information จากคำที่เกี่ยวข้องมาสู่คำที่ต้องการ และเวกเตอร์ output จาก Attention ก็คือ Features ที่เราต้องการนั่นเอง!!!
Feed Forward Network (FFN) คือการขยาย Linear Models ด้วยการนำ Linear Model หลายโมเดลมาทำงานต่อกัน (รายละเอียดอ่านในบทความแยก)
กระบวนการ (A) - (C) มองได้ว่าเป็นกระบวนการ Feature Extraction เบื้องต้นของ Transformers ในขณะที่ FFN ซึ่งหัวใจเป็น linear model จะทำกระบวนการ “ไขตู้กุญแจ” (linear model ตัวที่ 1) หรือ “หาทิศทางหรือตู้ที่เหมาะสม” เพื่อนำ “ของที่อยู่ในตู้” (linear model ตัวที่ 2) มาปรับปรุง features เพิ่มเติม ซึ่ง “การเก็บของในตู้” นี่เอง คือเทคนิค “การเก็บความจำหรือเก็บความรู้” ของ Transformers และ ChatGPT
ดั่งจะอธิบายในบทความถัดไปซึ่งเป็นบทความของ FFN อย่างละเอียดว่า linear models หลายโมเดลทำงานร่วมกันอย่างไร
ซึ่งเมื่อบล็อก (A) - (D) ทำงานต่อเนื่องกันเราก็จะได้ features ที่ดีขึ้นเรื่อยๆ จนกระทั่งสามารถจำแนกคำที่เหมาะสมได้ในท้ายที่สุด (เช่น การทำนายในรูปที่ 12)
(E) ประเด็นปลีกย่อยอื่น (บทความแยก อยู่ในระหว่างการเขียน) :
(E1) Nx หรือ การทำซ้ำหลายเลเยอร์ สังเกตในรูป 10 ทีมคิดค้น Transformers ได้มองบล็อกของ Attention + Feed Forward เป็นบล็อกใหญ่และกำกับด้วยเครื่องหมาย “Nx” ซึ่งหมายความว่าให้ทำบล็อกใหญ่นี้ N ครั้ง
ซึ่งจำนวน N นี้ทำให้เราเรียก Transformers ว่ามี N-layers ครับ และโดยทั่วไปยิ่ง N มีค่ามาก โมเดลจะยิ่งสามารถสร้าง features ที่ดีได้มากยิ่งขึ้น ทำให้เข้าใจประโยค Input มากขึ้น และทำนายคำถัดไปได้ดีขึ้น
ทำไมต้องทำซ้ำ N รอบ?? เราจะตอบคำถามนี้ในบทความแยกอย่างละเอียด ในที่นี้เราขออธิบายคร่าวๆ ว่าเป็นเพราะกระบวนการ Attention ยังมีความเป็น Local Operation บางส่วน ทำให้ในขั้นตอนแรกๆ มักจะส่ง information จากคำที่อยู่ใกล้กันเท่านั้น ในขณะที่เมื่อถึงใน layer หลังๆ Information ถึงจะมีการเชื่อมจากคำที่อยู่ไกลกันมากได้ดีขึ้น (ทั้งนี้เพราะปัจจัยสำคัญหนึ่งที่ Attention คิดในการส่ง Information หากัน ก็คือ Positional Encoding ที่คำที่ตำแหน่งใกล้กันมักจะมีเวกเตอร์ที่ส่งต่อ information กันได้ดี)
ไอเดียของการมี blocks หลาย blocks หรือหลาย layers นั้นเป็นไอเดียที่ทำให้ช่วงยุค 2010 - 2020 เรียกวงการ AI ว่า Deep Learning โดยคำว่า Deep มาการจินตนาการว่าโมเดลมีเลเยอร์เยอะมากจน “ลึก” จนมองได้ยาก
และไอเดีย Multi-Layers นี้กำเนิดจากโมเดล CNNs ที่กล่าวถึงในบทความปฐมบท AGI และดูรายละเอียดเพิ่มเติมได้ที่บทความ CNN ของ ThaiKeras ครับ(E2) Softmax เป็นเทคนิคทางคณิตศาสตร์ในการเปลี่ยนการทำนาย class ที่เราพูดถึงในหัวข้อที่ 2 แบบ Score ให้เป็น Probability (ความน่าจะเป็น) ทำให้การแปลความหมาย score ทำได้ง่ายขึ้น เหมือนที่แสดงในรูปที่ 12 (ส่วนผลลัพธ์ด้านบน)
(E3-1) Add & (E3-2) Norm หรือชื่อเต็มคือ Skip Connection และ Normalization ตามลำดับ เป็นเทคนิคสำคัญทางคณิตศาสตร์ที่ทำให้โมเดลเรียนรู้จากข้อมูลได้ดีขึ้น (ขั้นตอน F) และมีความเสถียรภาพมากขึ้น
(E4) Token (SubWord) vs. Word
ในบทความนี้ตั้งแต่ต้น เรากล่าวว่าโมเดลแบ่งประโยคเป็น “คำ” ซึ่งแท้จริงแล้วในทางปฏิบัติโมเดลจะแบ่งประโยคเป็น “Token” หรือส่วนที่ “ย่อย” กว่า “คำ” (อาจเรียกว่า Sub-Word)
ทำไมต้องทำให้ยุ่งยาก?? คำตอบคือในหลายภาษาเช่น ภาษาอังกฤษ หลายๆ คำมาจากรากศัพท์เดียวกัน เช่น “time”, “times”, “timing” หรือ “timed” สังเกตได้ว่าล้วนขึ้นต้นด้วย “tim” และคำต่อท้ายเช่น “es”, “ing” หรือ “ed” ก็พบได้ในคำกริยาแทบทุกคำ
ดังนั้นเพื่อให้โมเดลเรียนรู้ได้อย่างมีประสิทธิภาพ และไม่ต้องจำศัพท์เยอะเกินไป โมเดลก็จะแบ่งคำว่า “timing” ออกเป็น 2 tokens คือ “tim” และ “ing” แทนเป็นต้นครับ
ดังนั้นในรูป 11 จึงใช้คำว่า Input Embedding เพื่อหลีกเลี่ยงความสับสนว่าเป็น Token Embedding หรือ Word Embedding (อย่างไรก็ดี ในการทำความเข้าใจเราสมมติว่า token เป็น word ได้โดยไม่ทำให้รายละเอียดสำคัญเปลี่ยนแปลง)
(F) การสอนโมเดลจากข้อมูลมหาศาล ก่อนใช้งาน (บทความแยก อยู่ในระหว่างการเขียน) :
จากการทำงานโดยรวมของ Transformers จะเห็นว่า Attention สามารถตรวจสอบคำเกี่ยวข้องได้เองอย่างน่ามหัศจรรย์ หรือ FFN ซึ่งประกอบไปด้วย Linear Model ก็มีเมตริกซ์ A และเวกเตอร์ b ที่แบ่งข้อมูลได้อย่างมีประสิทธิภาพ สิ่งเหล่านี้เกิดจากการเรียนรู้ผ่านข้อมูลมหาศาลที่มีมนุษย์ช่วยในเบื้องต้น ซึ่งหัวข้อนี้เรียกว่า Machine Learning เป็นเรื่องใหญ่มากของศาสตร์ด้าน AI และเราจะทยอยอธิบายรายละเอียดในบทความย่อยเหล่านี้ครับ
Likelihood Principle หรือ Loss Function
Backpropagation Optimization
Masking (Encoder vs. Decoder)
Parameter Scaling & Overfitting, Out-of-Distribution, และ Bias
คำศัพท์ที่ต้องจำ :
Classification vs. LLMs vs. ChatBot vs. Agent
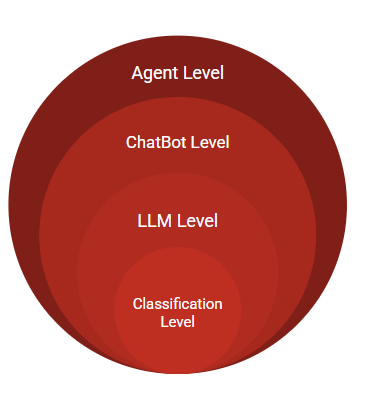
ในบทความต่างๆ ทั้งภาษาไทยและภาษาต่างประเทศ มีการใช้ศัพท์ LLMs (Large Language Model), ChatBot และ Agent เรียกแทน AI บ้าง ศัพท์เหล่านี้แท้จริงแล้วมีความสัมพันธ์กันดังรูป 13 ครับ
Classification : โมเดล AI ที่เชี่ยวชาญภาษามนุษย์ระดับ Transformers / ChatGPT ในส่วนย่อยที่สุดกำเนิดจาก Classification Model ดั่งที่เราอธิบายอย่างละเอียดในบทความนี้ครับ นั่นคือ ในการพูดคุยผ่านภาษามนุษย์ Classificatoin Model คือโมเดลที่ทำนาย “คำถัดไป” ทีละคำ
LLMs (Large Language Models) : โดยนิยาม หมายถึงโมเดลที่พูดคุย “ประโยค” ภาษามนุษย์ได้ ซึ่งตั้งแต่มีงานวิจัย AI มา ก็มีโมเดล Transformers โมเดลแรก (และอาจเป็นโมเดลเดียวในปัจจุบัน) ที่แต่งประโยคได้โดยสมบูรณ์
ดังนั้นถ้าเอาเฉพาะปัจจุบัน (2025)คำว่า LLMs ก็เลยจะแทบมีความหมายเช่นเดียวกับ คำว่า Transformers
ซึ่งอย่างที่อธิบายไปหลายรอบในบทความนี้ การแต่งประโยคของ Transformers เกิดจากไอเดียเอาการ “ทำนายคำ” ของ Classifiers หลายรอบจนได้ประโยคที่สมบูรณ์นั่นเอง ในรูปที่ 13 จึงแสดง LLMs ว่าเป็นโมเดลที่มาครอบ Classification Model อีกชั้นหนึ่ง
(ซึ่งงานวิจัย AI ในอนาคตอาจสามารถสร้าง LLMs ประเภทอื่นที่สามารถแต่งประโยคทั้งหมดได้โดยตรงไม่ต้องผ่านขั้นตอน Classification ก็เป็นได้ ถ้าถึงวันนั้น คำว่า LLMs ก็จะมีความหมายกว้างกว่าคำว่า “Transformers” )
ChatBot : คือการนำ LLMs มาปรับปรุงเพิ่มเติมเพื่อให้ “เชี่ยวชาญ” เรื่องการพูดคุยกับ users โดยเฉพาะ
สังเกตว่า LLMs โดยพื้นฐาน คือการแต่งประโยคต่อไปจากเดิมเรื่อยๆ โดยไม่สนใจว่า “ใครเป็นผู้พูด”
ดังนั้นถ้าเราจะประยุกต์ LLMs มาเป็น ChatBot โดยตรงโดยไม่ปรับปรุงอะไรเลย ถ้าเราใส่ Input เป็นคำถามที่เราสงสัยเพื่อให้ LLMs ตอบ LLMs อาจจะตอบก็ได้ (กรณีนี้ OK) หรือ LLMs อาจจะ “แต่งประโยคเพื่อถามเพิ่มเติม” ก็ได้ (ซึ่งกรณีนี้ไม่ OK เพราะผู้ใช้งานอย่างเราๆ ก็จะไม่ได้คำตอบที่ต้องการ)
ดังนั้นพอสอนในขั้นตอน LLMs เสร็จแล้วจึงต้องมีการสอนให้เชี่ยวชาญการแต่งประโยค “ตามคำสั่ง” อีกดัวย โดยขั้นนี้เป็นขั้นตอนถัดจาก Classification เรียกว่าขั้น Instruction ซึ่งสอนโดยใช้เทคนิค Reinforcement Learning (ดูบทความ “ปฐมบท AGI”)
นอกจากนี้การขยายจาก LLMs เป็น ChatBot ยังมีการเพิ่ม External Memory เพื่อนำ “บทสนทนาที่ผ่านมา” (Conversational History) มาเป็น Input ให้กับ LLMs อย่างอัตโนมัติ (ผู้ใช้งานไม่ต้องทำขั้นตอนนี้)
ยังไม่พอ ChatBot ที่เราใช้ในปัจจุบันยังอัพเกรดจาก LLMsให้มีความสามารถในการเรียกอ่าน Documents เพิ่มเติมหรือ Search Internet ได้อีกด้วย (ดูบทความ “5 Levels of AI Expertise”)Agent และ Multi-Agents : เป็นแนวคิดที่ขยายจาก ChatBot ไปอีกขั้น นั่นคือใช้ ChatBots หลายตัวมาร่วมกันทำงานเดียวกันให้มีประสิทธิภาพสูงสุด
โดยเริ่มจากให้ ChatBot แบ่งงานเป็นสัดส่วนและแบ่งงานแต่ละงานย่อยให้ ChatBots อีกหลากหลายตัวทำ และมี ChatBots คอยตรวจสอบผลลัพธ์ของแต่ละงานย่อย ก่อนจะมี ChatBots สุดท้ายนำผลลัพธ์ทั้งหมด (ดูในบทความ “5 Levels of AI Expertise” เช่นกัน)
เส้นตรงในระนาบ 2มิติ xy ที่แสดงในรูปนี้ แท้จริงแล้วเป็นเส้นตัดของระนาบ 3 มิติในสมการ
z = ax + by + c โดย z สามารถมองได้เป็น score ของดอกไม้สายพันธุ์ Setosa, โดยในตัวอย่างนี้ เราอาจจะทำนายว่าดอกไม้เป็นสายพันธุ์ Setosa ถ้า z มีค่าบวก และ “ไม่ใช่” สายพันธุ์นี้ถ้า z มีค่าลบ นั่นเอง
ในตัวอย่างนี้เรามี features 2 ค่าคือ (x,y) ทว่าในตัวอย่างอื่นถ้าเรามี features หลายค่า เช่น 9 features เราก็จะแทนค่า features ด้วยเวกเตอร์ x = (x1, x2, …, x9) โดย z = score = a.x + b โดย a.x คือ dot product ของเวกเตอร์ a = (a1, …, a9) และ x ซึ่งค่าของ a และ b จะถูกเรียนรู้จากข้อมูลสอน (อธิบายในบทความถัดๆ ไป) และกำหนดทิศทาง และตำแหน่งของ hyperplane
ซึ่ง Linear Model เป็นโมเดลคณิตศาสตร์ที่ถูกนำไปใช้ในแทบทุกองก์ความรู้ ไม่ว่าจะเป็น วิทยาศาสตร์ วิศวกรรมศาสตร์ เศรษฐศาสตร์ หรือสังคมศาสตร์ ดังนั้น ผู้ใฝ่รู้ควรตั้งเป้าศึกษาคณิตศาสตร์ด้านนี้ (Linear Algebra) ให้แตกฉานครับ
Feature Extraction หมายถึง การ “กลั่น” หรือ “สกัด” features ที่สำคัญออกมาจากข้อมูลนั่นเอง บางตำราเรียกว่า Feature Engineering
การเรียนรู้ค่า A และ b จากข้อมูลสอนใน Linear Model นั้นใช้ความรู้พื้นฐานของแคลคูลัส ซึ่งจริงๆ แล้ว Transformers ที่มีความซับซ้อนมากกว่า Linear Model เยอะมากๆ ก็ยังใช้หลักการคณิตศาสตร์เดียวกันนี้
การที่เวกเตอร์เบียดกันแบบนี้มีทั้งข้อดีและข้อเสียซึ่งพูดเพิ่มเติมในบทความถัดไปครับ
มาตรฐานทั่วไปมักแสดง vector ด้วย column ดังนั้นในที่นี่เมื่อเราพูดถึง แถว (row) ของ matrix แทน column เราจึงใช้สัญลักษณ์ transpose เพื่อบ่งบอกการเป็น row vector
การเปลี่ยนประโยคภาษามนุษย์ที่เราพิมพ์คุยใน ChatGPT เป็น vector feature as direction นี้จะเริ่มตั้งแต่ขั้นตอน “Input Embedding” ที่อธิบายคร่าวๆ ในหัวข้อที่ 4 ของบทความนี้
FFN (Feed Forward Network) ในรูปที่ง่ายที่สุดคือ Linear Models 2 ตัวมาเชื่อมกัน และมีฟังก์ชัน f(X) = max(0,x) หรือทีเรียกว่า RELU มาเชื่อมอยู่ตรงกลาง กล่าวคือ ในรูปง่าย FFN(x) = A(f(Bx)) โดย A และ B เป็น matrices เราจะอธิบายความหมาย ประโยชน์และที่มาของ FFN อย่างละเอียดในบทความถัดไป
บทความ AI ทั่วไปมักใช้คำว่า Next-Word Prediction มากกว่า Next-Word Classification ซึ่งในที่นี่มีความหมายเดียวกัน
เหตุผลเบื้องลึกในการแบ่ง “ข้อความ” เป็น “คำ” นี้คือวิธีอันชาญฉลาดที่ทำให้เรานิยาม “input space” ได้ — เทคนิคนี้เรียก input representation decomposition หรือแตกปัญหายากๆ ให้เป็นปัญหาง่ายๆ หลายๆปัญหา— นั่นคือถ้าเรา “ไม่” แบ่งเป็นคำๆ แล้วเรามอง “ข้อความที่เป็นไปได้ทั้งหมด” เป็น input แล้วนั้น มิติของ “ข้อความที่เป็นไปได้ทั้งหมด” นั้นเป็น infinite เนื่องจากข้อความนั้นมีความยาวเท่าใดก็ได้
นั่นคือในมุมมองทื่อๆ นี้ input จะอยู่บน infinite dimensional space
ตรงกันข้าม ถ้าเราแบ่ง (decompose) ข้อความเป็นคำ นั่นคือ ข้อความประกอบไปด้วย หลายๆ คำมาต่อกัน เรามอง input space เป็น space ของคำแทน ซึ่งอย่างน้อยจำนวน “คำ” ในภาษามนุษย์ก็มีจำกัด และทำให้เรานิยาม D-dimensional vector space มานำเสนอ และสร้างสมการคณิตศาสตร์มาประมวลผล “คำ” ได้
บล็อก SoftMax นี้แทบจะเป็น Linear Model ที่เหมือนที่อธิบายในหัวข้อ 2.2 คือทำสมการ Ax + b — โดย x ในที่นี้คือ feature vectors ที่ผ่านกระบวนการทั้งหมดของ Transformers มาแล้ว — ต่างกันที่มีการทำ normalize เพิ่มเติมเพื่อเปลี่ยนผลลัพธ์สุดท้ายเป็น “ความน่าจะเป็น“
อย่างไรก็ดีดูประเด็น E4 ที่เกี่ยวกับ Inputs เชิงลึกเพิ่มเติม โดยประเด็น E4 ไม่มีผลกับความเข้าใจในภาพรวม
ทำไมถึงต้องทำนาย “คำถัดไป” จากเพียง “คำสุดท้าย” ของ Input?? คำตอบคือเป็นการ design ของทีมคิดค้น Transformers เพื่อให้กระบวนการ classification โดยรวมทั้งหมด ทำได้ง่ายและเป็นระเบียบ ซึ่งถ้าผู้อ่านคิดโมเดลอื่นขึ้นมาเอง อาจจะออกแบบให้แตกต่างออกไปได้