

5 วิถีแห่งความเชี่ยวชาญ AI Expertise ที่คุณต้องรู้
5 Levels of AI Expertise - พัฒนาความรู้ ความเชี่ยวชาญด้าน AI แบบไหนให้เหมาะสมกับคุณ

นับแต่ปี 2022 ChatGPT ได้ปฏิวัติให้มนุษย์ทุกคนบนโลกสามารถเข้าถึงเทคโนโลยี AI ได้โดยไม่มีต้นทุน ซึ่งนอกจากจะเป็นการพลิกวิถีชีวิตของมนุษย์อย่างเรา ที่อยู่ดีก็มีผู้ช่วยอันชาญฉลาดอยู่ข้างกายพร้อมให้คำแนะนำ ปรึกษาตลอดเวลา
ยังเป็นการพลิก “การเรียนรู้” ศาสตร์ของ AI สำหรับพวกเราทุกคนอีกด้วย

ก่อนหน้า ChatGPT คนที่อยากเชี่ยวชาญเรื่อง AI นั้นผู้ศึกษาต้องเข้าไปทำความเข้าใจภาคทฤษฎีไม่มากก็น้อย รวมทั้งภาคปฏิบัติทั้ง “การเขียนโปรแกรมสอน” ให้ AI มีความฉลาดในงาน “เฉพาะด้าน”
(เช่น บทความปี 2018 ของ ThaiKeras เล่าการเตรียมสิ่งจำเป็นในการพัฒนาระบบ AI)
แต่เนื่องจากโมเดล ChatGPT นั้นอัพเกรดจาก AI รุ่นก่อนที่มีความรู้ “เฉพาะด้าน” อย่างมาก นั่นคือ ChatGPT มีความรู้ “รอบด้าน” (General) อยู่แล้วในแทบทุกเรื่อง อาจเรียกได้ว่า ChatGPT เป็นจุดเริ่มต้นของ AI ยุคใหม่ นั่นคือ AGI (Artificial General Intelligence)
การเขียนโปรแกรมสอน ChatGPT (หรือโมเดล AI อื่นที่ฉลาดใกล้กัน) จึงแทบไม่มีความจำเป็นสำหรับการใช้งานส่วนตัวหรือธุรกิจทั่วๆ ไป อาจจะยกเว้นงานเฉพาะด้านสุดๆ เช่น งานวิจัยหรืองานบริษัทที่มีข้อมูลเฉพาะทางมหาศาลเท่านั้น
ดังนั้นการพัฒนาเพื่อให้ตัวเองเป็นผู้เชี่ยวชาญในยุคใหม่ของ AGI นี้ เราควรตั้งเป้าเรียนรู้อะไร? โดยทั่วไปอาจมีคำแนะนำหลายแบบจากผู้รู้หลายท่าน เช่น
ฝึกตั้งคำถาม พูดคุยกับโมเดล AI ให้ได้คำตอบดีที่สุด (Prompting)
เขียนโปรแกรมครอบโมเดล AI ให้ทำงาน routine หรือ งานหลากหลายได้สะดวก (Agentic AI)
ศึกษาโมเดล AI อย่างลึกซึ้งทั้งในแง่สมการคณิตศาสตร์ และการเขียนโปรแกรมสร้างมันขึ้นมา
แท้จริงแล้ว ทุกแนวทางก็ถือเป็นวิถีที่จะทำให้เราเป็นผู้เชี่ยวชาญด้าน AI เพียงแต่ขึ้นอยู่กับว่างานหลักที่เราต้องใช้งาน AI อยู่ในรูปแบบไหน และเราเองปรารถนาที่จะไปลึกแค่ไหน
จึงเป็นที่มาของบทความนี้ ที่จะแบ่งการพัฒนาความรู้ด้าน AI เป็น 5 วิถี เพื่อให้เป็นผู้เชี่ยวชาญเรื่อง AI ในแบบที่เหมาะสมกับตัวคุณเอง
5 วิถีนี้จริงๆ แล้วเรียงจากง่ายไปยาก เราจึงสามารถมองได้อีกแบบเป็น “บันได 5 ขั้น” หรือ “5 Levels of AI Expertise” ก็ได้ครับ
5 Levels of AI Expertise
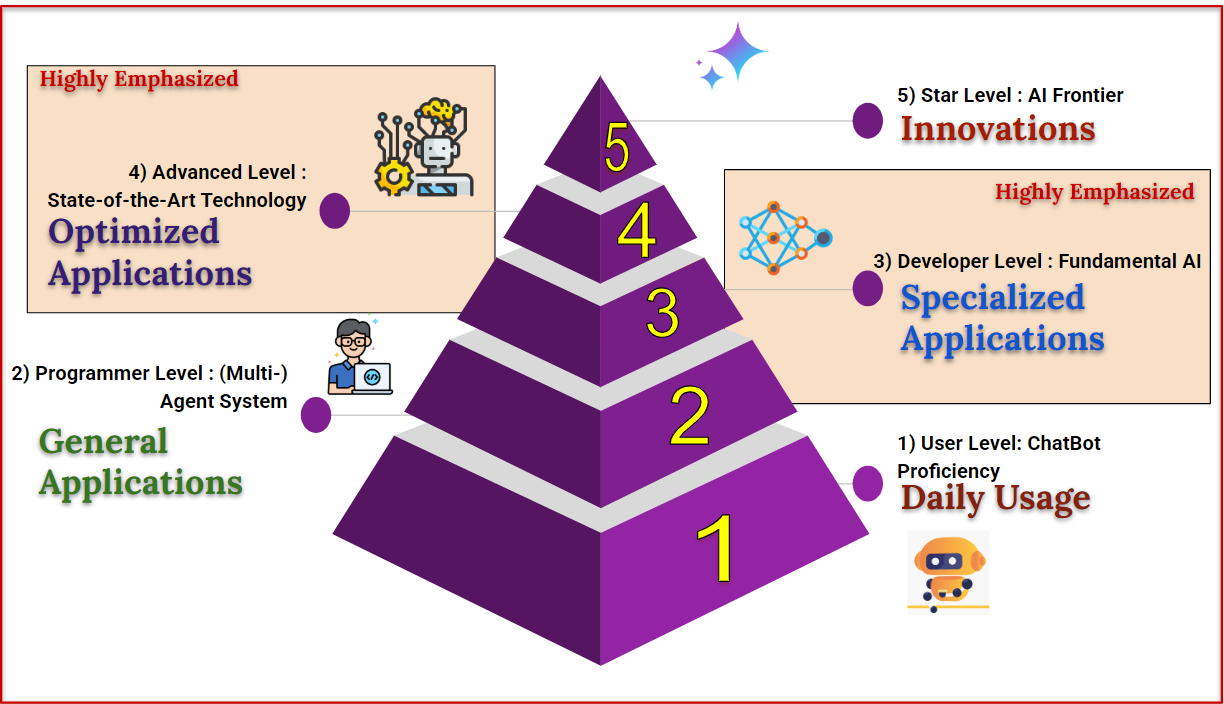
รูปที่ 1 สรุป 5 วิถีหรือ พิระมิด 5 ขั้นในพัฒนาตัวเองให้เป็นผู้เชี่ยวชาญด้าน AI ดังนี้
ระดับผู้ใช้งาน (User Level) : สำหรับงานส่วนตัวและธุรกิจทั่วไป ต้องเชี่ยวชาญเรื่อง Prompting และติดตามเรียนรู้ tools และ technology ใหม่ๆ สม่ำเสมอ เพื่อให้ได้คำตอบจาก AI ที่สมบูรณ์ มีเหตุผล ตรงตามความต้องการมากที่สุด
ระดับโปรแกรมเมอร์ (Programmer Level): สำหรับการนำ AI ไปต่อยอดสร้าง Applications หรือการใช้งาน AI กับปัญหาที่มีความซับซ้อนมากขึ้น โดยปัญหาเหล่านี้ต้องมีการปรึกษา AI ซ้ำหลายรอบ (iterations) หรือมีการตรวจหรือพัฒนาคำตอบ ต้องมุ่งเน้น Agentic Programming เพื่อให้การติดต่อ AI หลายรอบนี้ทำได้อย่างง่ายและประสิทธิภาพสูง
ระดับนักพัฒนา (Developer Level): สำหรับบริษัท นักวิจัย นักวิทยาศาสตร์ วิศวกรด้าน AI ที่จริงจังและต้องการปรับเปลี่ยนพฤติกรรมและความรู้ของ AI อย่างมีนัยสำคัญ การนำ AI ไปช่วยเหลือในงานผลิตภัณฑ์เฉพาะทาง เช่น ออกแบบโมเลกุลยา เป็นต้น ควรต้องศึกษา AI Fundamental อย่างลึกซึ้ง เนื่องจากต้องมีการออกแบบโปรแกรมการสอน และข้อมูลสอน AI ให้ถูกต้อง
(การแข่งขันเขียนโปรแกรมบน Kaggle ขั้นเริ่มต้นจนถึงเหรียญทองแดง จะอยู่ราวๆ ขั้นนี้)ระดับนักพัฒนาขั้นสูง (Advanced Level): สำหรับองค์กรขนาดใหญ่ ที่ไม่เพียงต้องการปรับความรู้และพฤติกรรมของ AI แต่ยังต้องการรีดเค้นให้ AI มีประสิทธิภาพสูงที่สุด (แม่นยำ เร็ว และประหยัดที่สุด) ต้องเรียนรู้ตลอดเวลาเพื่อประยุกต์ใช้เทคนิคขั้นสูง และดัดแปลงงานวิจัยใหม่ๆ ที่ได้รับการพิสูจน์และยอมรับในวงกว้าง โดยอาจต้องมีการแก้ ดัดแปลงโค้ด จาก OpenSource อย่างมีนัยสำคัญ
(การแข่งขันเขียนโปรแกรมบน Kaggle ชิงระดับเหรียญทองหรือเหรียญเงิน น่าจะอยู่ในขั้นนี้)ระดับดาราในวงการ (Star Level) : หรืออาจเรียกว่า นักวิจัยระดับโลก สำหรับนักวิจัยที่อยู่ในวงการและมีส่วนร่วมในการขับเคลื่อนทิศทางด้วยการคิดค้นนวัตกรรม AI ในระดับสากล ต้องมีพื้นฐาน Level 3 และ 4 อย่างแข็งแรง รวมทั้งเข้าใจงานวิจัยในงานประชุมวิชาการด้าน AI ที่ดีที่สุด เช่น ICLR, NIPS หรือ ICML อย่างลึกซึ้งทั้งภาคทฤษฎี สมการคณิตศาสตร์ และการ Implementation
โดยรายละเอียดของทักษะในแต่ละ Level ที่เราควรเรียนรู้แสดงเพิ่มเติมในรูปที่ 2 ครับ ซึ่งถ้าใครยังไม่แน่ใจว่าจะตั้งเป้าไปที่ Level ไหนดี มาตามอ่านรายละเอียดในหัวข้อถัดไปกันครับ
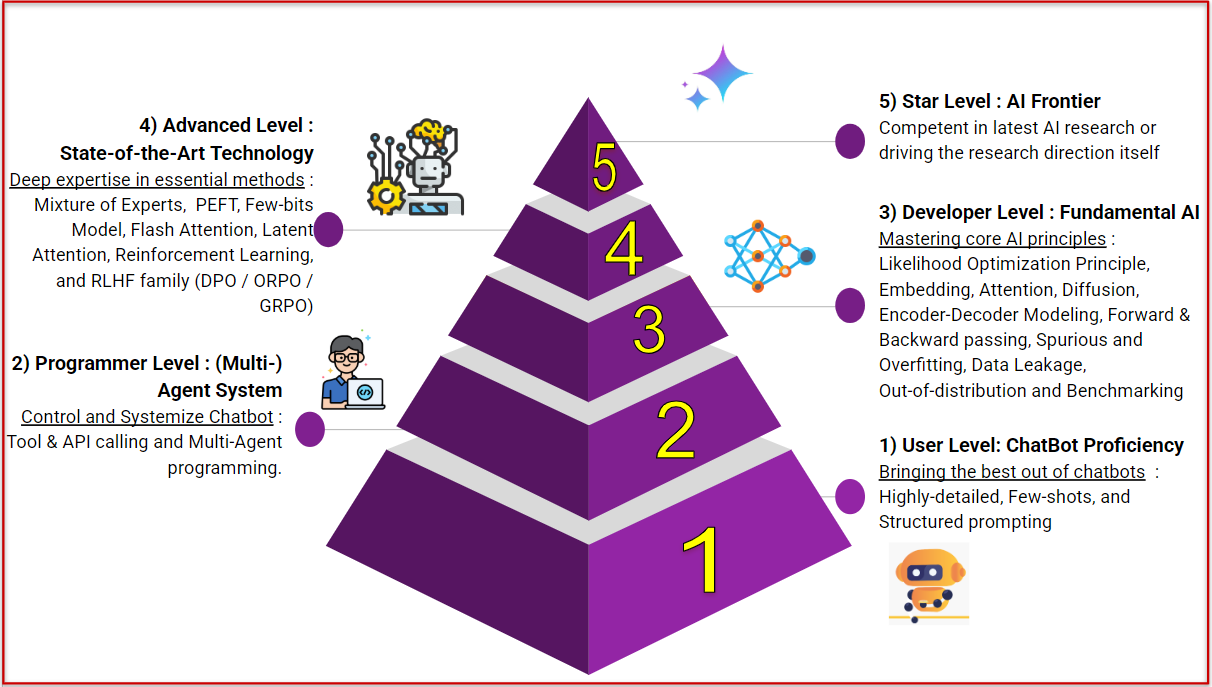
Level 1: ผู้ใช้งานทั่วไป เชี่ยวชาญเรื่อง Prompting
ใครๆ ก็สามารถคุยกับ ChatBot ได้จริง ทว่าการถามคำถามให้ดี มีผลกับคำตอบของ ChatBot อย่างมาก ดังนั้นผู้ใช้ต้องมีความรู้ที่เรียกว่า prompting หรือก็คือการคุยกับ AI อย่างเป็นระบบ เพื่อให้ได้คำตอบที่แม่นยำ ละเอียด สมเหตุผล
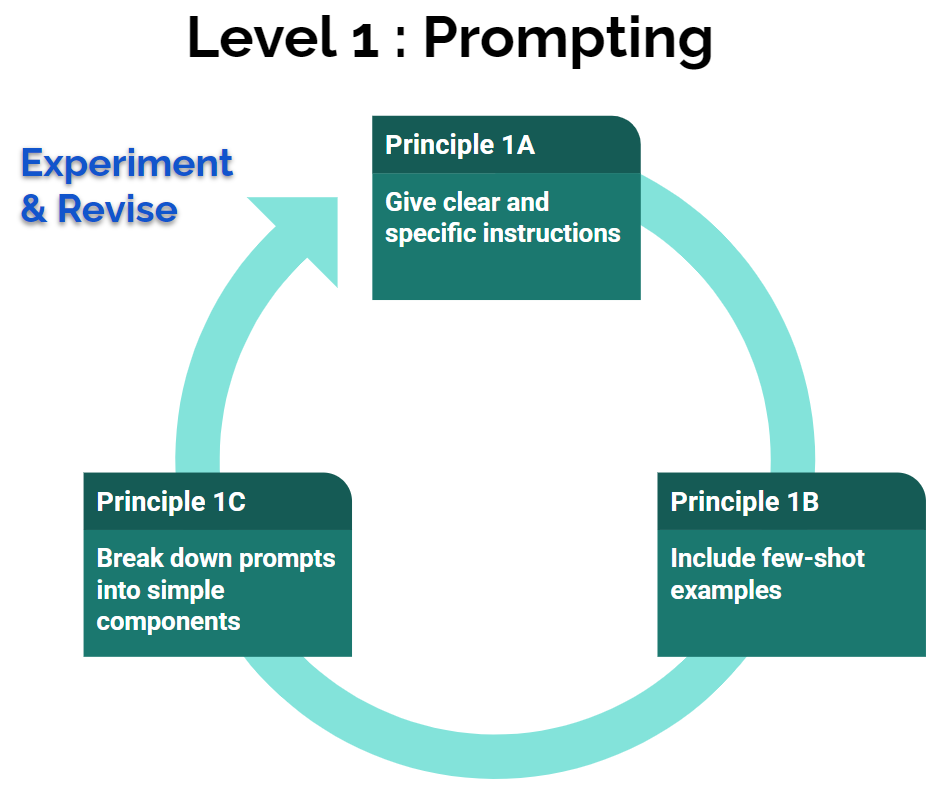
โดยทีมอย่าง OpenAI และ Google AI ได้ให้คำแนะนำเทคนิค prompting ไว้มากมาย (คลิกที่ลิงก์ของทั้งสองทีมเพื่อดูเพิ่ม) ในรูป 3 เราสรุปเหลือเพียง 3 หลักพื้นฐานที่เราคิดว่าสำคัญที่สุดของ prompting ไว้ ดังนี้
หลักพื้นฐาน 1A: อธิบายสิ่งที่อยากได้คำตอบให้ชัดเจน และอธิบายรูปแบบ output format ที่ต้องการ
ตัวอย่างที่ไม่ระบุความต้องการให้ชัด ❌:
Write a fantasy story about OpenAI. ตัวอย่างที่ดี ✅:
Write a short inspiring story about OpenAI, focusing on the recent DALL-E product launch (DALL-E is a text to image ML model) with this output format. Story name:
Character names: <comma_separated_list_of_character_names>
Specific Genres:
General themes:
Story:
{input text}หลักพื้นฐาน 1B: ให้ตัวอย่าง ถาม-ตอบ ที่เราคาดหวัง ก่อนจะถามคำถามที่แท้จริง
ตัวอย่างที่ประสิทธิภาพน้อย ❌ (ไม่แสดงตัวอย่างที่เราต้องการ): Zero-shot
Extract keywords from the below text.
Text: {input text}
Keywords:ตัวอย่างที่ให้ตัวอย่าง AI เข้าใจถึงคำตอบที่เราต้องการ ✅ Few-shot
Extract keywords from the corresponding texts below.
## Text 1: Stripe provides APIs that web developers can use to integrate payment processing into their websites and mobile applications.
Keywords 1: Stripe, payment processing, APIs, web developers, websites, mobile applications
## Text 2: OpenAI has trained cutting-edge language models that are very good at understanding and generating text. Our API provides access to these models and can be used to solve virtually any task that involves processing language.
Keywords 2: OpenAI, language models, text processing, API.
## Text 3: {input text}
Keywords 3:หลักพื้นฐาน 1C: แยกสิ่งที่เราต้องการในกรณีเป็นงานยาก ให้เป็นเรื่องง่ายๆ หลายๆ เรื่อง
ตัวอย่างที่ไม่ดี ❌: ขอให้ ChatBot สร้างโปรแกรมที่ซับซ้อนให้เรา โดยเราระบุความต้องการทั้งหมดลงไปในครั้งเดียว
Write Python code to scrape product information (name, price, description) from an e-commerce website (e.g., Amazon) for a specific product URL. ตัวอย่างที่ดี ✅: จากตัวอย่างข้างต้น เราอาจพยายามแบ่งความต้องการออกเป็นเรื่องย่อยๆ แล้วค่อยๆ ถามเพื่อให้ ChatBot ช่วยทำทีละขั้น
{sub-prompt-1}
You: Write Python code to fetch the HTML content of a given URL. Bot: (คำตอบที่1 จาก ChatBots)
{sub-prompt-2}
You: Write Python code using Beautiful Soup to parse the HTML and extract the product name, price, and description.
Bot: (คำตอบที่2 จาก ChatBots)
{sub-prompt-3}
You: Combine the code from the previous steps into a complete function that takes a product URL as input and returns the product information (or an error message).
Bot: (คำตอบที่3 จาก ChatBots)
{sub-prompt-4}
You: Write a short example demonstrating how to use the function with a sample URL.
Bot: (คำตอบที่4 จาก ChatBots) จริงๆ แล้ว คนเก่งที่พร้อมช่วยปรับ prompt เราให้ดีขึ้นได้โดยอัตโนมัติก็คือตัว ChatBot นั่นเองครับ สำหรับสองเทคนิคง่ายๆ ในการให้ ChatBot ช่วยปรับ prompt ของเราก่อนที่มันจะตอบคำถามเรา ให้ลองอ่านบทความนี้ใน linkedin ครับ
นอกจาก ChatBots แล้วยังมีเทคโนโลยี AI อื่นๆ ที่ผู้ใช้ทั่วไปใช้งานได้ง่าย และฟรี (จำกัดจำนวน) เช่นโปรแกรมสร้างรูป1 หรือสร้างวิดิโอ2 ซึ่งเราต้องใช้ prompting ในการสั่งให้พวกมันทำงานให้เราเช่นกัน
และเมื่อนำทุกโปรแกรมมาประกอบกัน เราจะสามารถทำงานได้มากมายหลากหลาย
ดังนั้นนอกจาก Prompting ในระดับผู้ใช้งานที่ต้องการเชี่ยวชาญเรื่อง AI (ใน Level 1) จึงควรหมั่นเรียนรู้เทคโนโลยีใหม่ๆ ที่ดีและใช้งานไม่ยากตลอดเวลาครับ
สำหรับผู้ใช้งานที่ใช้ภาษาไทยเป็นหลัก ขอแนะนำ AI สัญชาติไทยที่ชื่อว่า อลิสา ซึ่งเป็นโมเดลที่คุยภาษาไทยได้อย่างธรรมชาติ และยังสร้างรูปและวิดิโอได้ มีตัวอย่าง prompts ที่หลากหลายให้ลองใช้งานครับ3
Level 2: โปรแกรมเมอร์ มุ่งเน้น Agent Programming
หัวใจของ Level-2 ก็คือ การเขียนโปรแกรมครอบ AI อีกขั้นหนึ่ง
การเขียนโปรแกรมครอบ AI/ChatBot ซึ่งมักเรียกกันว่า “Agent(ic) Programming” นั้นพูดง่ายๆ ก็คือ การพูดคุยกับ AI/ChatBot โดยการเขียนโปรแกรมผ่าน API แทนที่จะคุยกันตรงๆ ผ่าน AI app หรือผ่านเว็บแบบ users ทั่วไป4
แล้วทำไมต้อง Level-2 เราต้องการอะไรมากกว่าการสร้างคำตอบที่มีคุณภาพที่เราเรียนรู้มาจากความเชี่ยวชาญใน Level-1?
3 ตัวอย่างที่ชัดเจนว่า Level-1 อาจไม่ดีพอคือ งานที่ต้อง (A) ทำซ้ำ (B) ต้องปรับปรุงคำตอบ และ (C) ต้องแตกเป็นงานย่อย งานเหล่านี้มันจะ “ถึก” มากถ้าเราต้องมานั่งพิมพ์ถามตอบด้วยตัวเราเอง เรามาดูรายละเอียดกันครับ
2A. งานทำซ้ำ (Iteration Jobs) - เช่น ในการให้ AI ช่วยตรวจสอบความถูกต้องของข้อมูลสินค้าที่ได้รับหลากหลายชิ้น แทนที่เราจะมานั่งถาม AI ให้ช่วยตรวจในสินค้าแต่ละชิ้น จะดีกว่าไหม ถ้าเราเขียนโปรแกรมวนลูปครอบ AI ให้เช็คทุกชิ้น และสรุปเป็น report ให้เราอัตโนมัติ
2B. งานปรับปรุงแก่ไช (Reflection / Judging Jobs) - ทราบหรือไม่ว่า AI สามารถวิเคราะห์จุดอ่อนในคำตอบของตัวเองได้ และเมื่อนำคำวิเคราะห์นั้นไปปรับปรุง จะทำให้คำตอบเดิมยิ่งดีขึ้นไปอีก กระบวนการมักนี้เรียกว่า “Reflection” (บางครั้งเรียกว่า “AI as a Judge” หรือ “Verifier” )
อย่างไรก็ดี กระบวนการ Reflection / Judging นี้คงจะ “ถึกทน” พอดูถ้าพวกเราจะต้องมานั่งพิมพ์ reflect และปรับปรุงคำตอบเองทุกครั้ง ดังนั้นการ “เขียนโปรแกรมครอบ AI” ให้ทำ reflection และปรับปรุงคำตอบจากการ reflect ทุกครั้ง จึงสะดวกกว่ามาก
2C. งานซับซ้อน (Complex jobs) - ถ้าเราต้องเจองานที่ซับซ้อนมากๆ จำนวนหลายงาน งานเหล่านั้นยังควรต้องแตกเป็นงานย่อยหลายงานย่อยลงไปอีก (เช่น ต้องทำหลายงานที่คล้ายกับตัวอย่างใน Level-1C) แทนที่เราจะมานั่งออกแบบงานย่อยด้วยตัวเอง เหมือนตัวอย่างใน 1C
จะดีกว่าไหมถ้าเราเขียนโปรแกรมให้ AI แตกเป็นงานย่อยให้อัตโนมัติ (auto planning) รวมทั้งเรายังสามารถเขียนโปรแกรมเพิ่มให้ AI ทำแต่ละงานย่อย และนำผลลัพธ์ทั้งหมดมาสรุปรวมให้เราเองโดยอัตโนมัติอีกด้วย
ปัจจุบันมี Agentic Programming Frameworks ที่เป็นส่วนขยายของ Python หลากหลาย เช่น CrewAI, LlamaIndex, DSPy และ LangChain/Graph ซึ่งสำหรับผู้เริ่มต้นขอแนะนำ CrewAI ที่ใช้งานง่าย5 ส่วนมือโปรที่อยากควบคุมโมเดลแบบละเอียดแนะนำ DSPy ครับ 6 (ใน footnotes แนะนำ tutorial เพื่อให้ศึกษาต่อได้ง่ายๆ ครับ)
ล่าสุดในปี 2025 ทาง Huggingface ได้ออก Agentic Framework ของตัวเองขึ้นมาคือ smolagents ซึ่งเรายังไม่มีโอกาสได้ลองใช้ แต่นับว่าเป็นอีก framework นึงที่ดูมีศักยภาพมาก
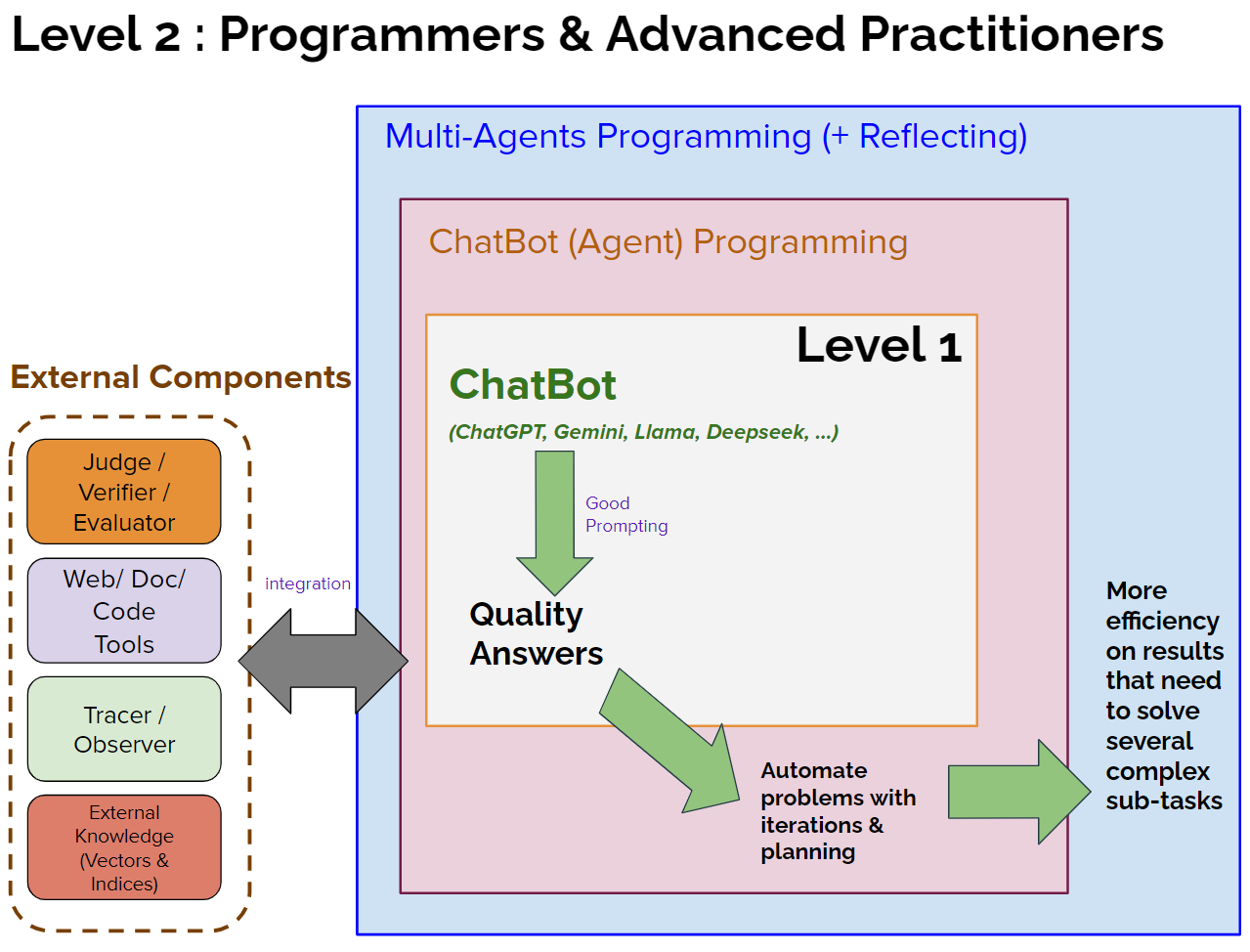
รูป 4 แสดงถึงประโยชน์ภาพรวมของการอัพเกรดฝีมือจาก Level-1 ไปยัง Level-2 ซึ่งนอกจากเหตุผล (A)-(C) ข้างต้น ยังมีเรื่องอื่นๆ ที่สำคัญโดยเฉพาะการใช้งาน AI ระดับมืออาชีพที่ต้องนำ AI ไปเป็นส่วนหนึ่งของ Application ครับ อาทิเช่น
2D. การใช้ Tools - การเขียนโปรแกรมครอบ AI ทำให้เราเรียกใช้ Tool อื่นๆ ได้ เช่น Web Search, Document Reading และ Code Execution เป็นต้น ทำให้เราสามารถควบคุมหรือประมวลผล input ก่อนที่จะส่งไปยัง ChatBot หรือ หลังจากได้ output จาก ChatBot แล้ว เช่น อ่านข้อมูลจาก Document แล้วนำไปถาม ChatBot หลังจากนั้นนำคำตอบของ ChatBot ไป Search หาข้อมูลยืนยันจาก Web เป็นต้น7
นอกจากนี้อีก tool ที่สำคัญมากสำหรับการใช้งานในองค์กร คือ Vector Database8 ที่อนุญาตให้เราเปลี่ยนฐานข้อมูลของเราเองให้อยู่ในรูปที่ AI เข้าใจและนำมาอ้างอิงได้ เช่น รายละเอียดและประวัติการซื้อขายผลิตภัณฑ์ต่างๆ ในบริษัททั้งหมดของเราเอง ซึ่ง AI โดยทั่วไปจะไม่มีข้อมูลเหล่านี้ ด้วยพลังของ tools จะทำให้ AI เข้าใจ ช่วยปรับปรุง หรือช่วยวางแผนเรื่องต่างๆ ที่เกี่ยวผลิตภัณฑ์ภายในของบริษัทได้
2E. Multi-Agent System - ระบบ Multi-Agents หรือการเขียนโปรแกรมให้ AI หลายๆ โมเดลมาช่วยงานกัน แบ่งงานเป็นสัดส่วน ถือเป็นขั้นที่แสดงพลังสูงสุดของ Agentic Programming ยกตัวอย่างในรูปที่ 5

รูปที่ 5 แสดงตัวอย่างการแก้โจทย์ที่ซับซ้อนระดับ “Software Development” ด้วย multi-agents system ซึ่งจากรูปเราให้ AI หลายโมเดลแทนแต่ละตำแหน่งงาน รับผิดชอบงานที่ต่างกัน และส่งงานผ่านต่อกันได้ เช่น ในตัวอย่างนี้ AI-CEO จะเป็นผู้กำหนดเป้าหมาย โดยมี AI-CTO มาช่วยเปลี่ยนจากเป้าหมายให้เป็น “Technical Requirements” จากนั้นส่งต่อให้ AI-Programmer เป็นผู้ implement และ AI-Reviewer มาช่วยตรวจสอบความถูกต้อง แล้วส่งกลับให้ “AI-Programmer” แก้ไข ฯลฯ
การใช้ Multi-Agent มีข้อดีอย่างไร?
ประสิทธิภาพ - ได้มีการทดสอบพบว่า การแตกปัญหาใหญ่ที่ซับซ้อน เป็นปัญหาเล็กทีละขั้นนั้นมีเพิ่มประสิทธิภาพความถูกต้องของผลลัพธ์อย่างมีนัยยะสำคัญ9 โดยตัวอย่างล่าสุดคือ OpenAI DeepResearch ซึ่งพัฒนาความแม่นยำของ ChatGPT-O3 ที่ว่าเหนือมนุษย์แล้วไปอีกกว่าเท่าตัวบนการทดสอบที่ยากที่สุดที่มนุษย์จะคิดได้อย่าง “Humanity’s Last Exam”
ทำลายข้อจำกัดเรื่อง output - โดยทั่วไปโมเดล AI จะมีการกำหนดขนาดความยาวสูงสุดของ output (output limit) การแตกปัญหาย่อยทำให้แต่ละปัญหาย่อยสามารถตอบได้ยาวเท่ากับ limit นั้น เทียบกับการสอบถาม ChatBot ในครั้งเดียวที่ทุกปัญหาย่อยจะต้องใช้ limit นี้ร่วมกัน10
ประหยัดด้วยโมเดลเล็ก - การทำ Multi-Agent สามารถประหยัด cost กว่า single-agent ได้ ถ้าในการแก้งานเล็กๆ หรือง่ายๆ เราเรียกโมเดลที่มีขนาดเล็กมาก ราคาถูกมาใช้งานแทนโมเดลตั้งต้นซึ่งอาจจะแพงกว่า
เพิ่มความเร็วด้วย Parallism : การเรียกใช้งาน AI API จากหลายค่าย ถ้าเราเรียกพร้อมๆ กันด้วย Asynchronus Programming จะทำให้โมเดลแต่ละตัวทำงานพร้อมๆ กัน และทำให้เราได้หลายๆ output มาในเวลาเร็วกว่าการใช้งานโมเดลเดียว
อย่างไรก็ตามการเขียนโปรแกรม Multi-Agent System นั้นมีความท้าทาย เพราะเราจะควบคุมหรือตรวจสอบสิ่งที่ AI Agents แต่ละโมเดลคุยกันได้ยาก อาจจำเป็นต้องใช้ tool เช่น LangSmith ซึ่งเป็น tool เสริมในการตรวจสอบการติดต่อพูดคุย input/output ของแต่ละ agent ครับ
สำหรับผู้ใช้งานทั่วไประดับ Level-1 ก็สามารถลองเล่น Multi-Agent ได้ใน อลิสา AI สัญชาติไทยที่มีบริการ “/Goal” ซึ่งก็คือการเรียกใช้ Multi-Agent ที่ทีมอลิสาสร้างไว้แล้ว ให้เราใช้งานง่ายๆ ครับ11
Level 3: นักพัฒนาต้องแม่น AI Fundamental
หัวใจของ Level-3 คือ ความสามารถในการสอน AI ให้เรียนรุ้เรื่องใหม่ๆ ได้ และจะเป็นเป้าหมายหลักของชุดบทความ ThaiAGI SuperSeries 2025
ทำไมต้องสอน AI ในเมื่อ AI อ่านหนังสือและเว็บมาแล้วทั้งโลก และเข้าใจแทบจะทุกภาษา?
ถึงแม้โมเดล AI จะเรียนรู้ข้อมูลทุกอย่างที่ถูกเขียนขึ้นมาด้วยภาษาของมนุษย์แล้วก็จริง ทว่าถ้าเราต้องการให้ AI ช่วยเหลือในงานอื่นนอกเหนือจาก ภาษามนุษย์ ล่ะ?
ยกตัวอย่างเช่น บริษัทผลิตยาต้องการศึกษาเรื่องการทำปฏิกริยาระหว่าง โมเลกุลยา และเอนไซม์ตัวหนึ่งในร่างกายมนุษย์ ถ้า AI จะวิเคราะห์โอกาสในการทำปฏิกริยาเคมีนี้ได้ AI ต้องเข้าใจภาษาของโมเลกุล และภาษาของโปรตีน (เพราะเอนไซม์เป็นโปรตีนชนิดหนึ่ง)

ภาษาโปรตีน หลักๆ ประกอบด้วย ตัวอักษร 20 ตัวแทนกรดอะมิโนพื้นฐาน 20 ชนิด นำมาเรียงร้อยกันดังแสดงในรูป 6 โดยโปรตีนในธรรมชาติที่เราทราบมีหลายพันล้านชนิด12 และมีการเรียงตัวของกรดอะมิโนที่ต่างกันออกไป
โมเดลเช่น ChatGPT, Gemini, Lllama หรือ DeepSeek อาจจะพอมีความรู้เรื่องภาษาโปรตีนบ้าง แต่ก็จะไม่เชี่ยวชาญถึงขนาดทราบรายละเอียดของโปรตีนที่แตกต่างกันเป็นพันล้านชนิดนี้
นอกจากโปรตีนแล้ว เฉพาะโมเลกุลขนาดเล็กก็ยังมีมากกว่า 1 แสนล้านชนิด13 และมีภาษาที่แตกต่างกันออกไปอีก14
ดังนั้นบริษัทที่ต้องการทำความเข้าใจปฏิกริยาเคมีของโปรตีน และโมเลกุลจึงจำเป็นต้องสอน AI เพิ่มเติมให้เข้าใจถึงภาษาใหม่นี้ได้
ในทางธุรกิจอื่นๆ ถ้าบริษัทใดมีผลิตภัณฑ์ของตัวเองเป็นหลักหมื่นหรือหลักแสนชนิด ก็อาจจะอยากสอนโมเดล AI15 เพิ่มเติมในผลิตภัณฑ์ของตัวเอง ซึ่ง AI อาจจะไม่รู้ลึกในรายละเอียดเนื่องจากข้อมูลเหล่านี้เป็นข้อมูลเฉพาะ และอาจเป็นความลับของแต่ละบริษัท
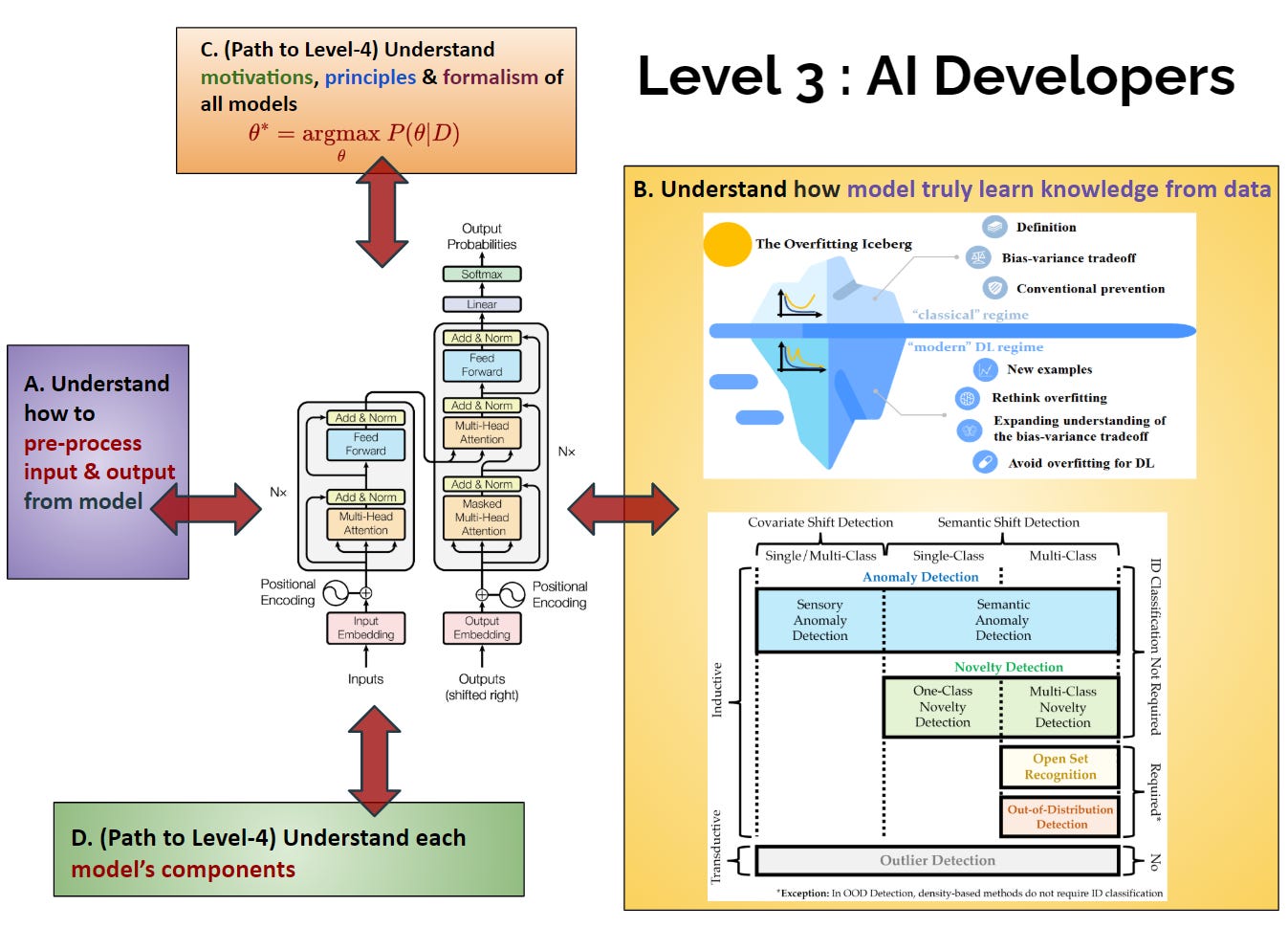
รูป 7 นั้นแสดง 4 เรื่องหลักที่ผู้เชี่ยวชาญ AI ใน Level-3 นี้ควรเข้าใจเพื่อที่จะสอน AI ให้เรียนรู้เรื่องใหม่ๆ ได้โดยเฉพาะ (3A) และ (3B) ส่วน (3C) และ (3D) นั้นจะนำทางไปสู่ความเชี่ยวชาญ Level-4
4 แก่นหลักใน AI Expertise Level-3
(3A) จัดเตรียมข้อมูลให้อยู่ในรูปที่โมเดลเข้าใจได้(3B) เข้าใจแก่นของ “การเรียนรู้”
(3C) เข้าใจสมการเป้าหมายของการเรียนรู้
(3D) เข้าใจแต่ละส่วนประกอบของโมเดล ทั้งสมการคณิตศาสตร์ และการเขียนโปรแกรม
(3A) จัดเตรียมข้อมูลให้อยู่ในรูปที่โมเดลเข้าใจได้
มาขยายความกันเริ่มจาก (3A) โมเดลแต่ละประเภทและการ implement ของโปรแกรมเมอร์แต่ละทีม จะมีรูปแบบ input ที่ต้องการไม่เหมือนกัน ดังนั้นในขั้น (3A) นี้ พวกเราต้องเรียนรู้ spec ของ input / output ของโมเดลที่เราต้องการใช้งานก่อน โดยเฉพาะ input เพื่อที่จะได้นำไปสอนโมเดลได้16
โดยทั่วไปในขั้น (A) นี้เรามักดูตัวอย่างจากผู้สร้างโมเดลได้ไม่ยาก ขอยกตัวอย่าง เช่น Unsloth AI เป็นทีมที่เป็น expert ด้านการสอนโมเดล AI ได้จัดเตรียม notebook ตัวอย่างการสอนโมเดล AI ให้เรียนรู้เรื่องต่างๆ ดังตัวอย่างนี้
Colab Notebook ตัวอย่างการสอนโมเดล Transformers Phi-4
ในขั้น (A) เราสามารถดูตัวอย่างได้จากหัวข้อ “Data Prep” ในลิงก์ดังกล่าว
(3B) เข้าใจแก่นของ “การเรียนรู้”
โมเดลจะรู้ในสิ่งที่สอนจริงหรือไม่? ขึ้นอยู่กับขั้นนี้
ถัดมาหลังจากที่เราเตรียมข้อมูลในขั้น (3A) แล้ว notebook ของ Unsloth ดังกล่าวได้จัดเตรียมให้เราสามารถ “สั่ง” ให้โมเดลเรียนรู้ได้ เพียงรัน cells ในหัวข้อ “Train the Model” ใน notebook ข้างต้น
อย่างไรก็ดี เราจะทราบได้อย่างไรว่าโมเดลเรียนรู้ได้จริง? โดยทั่วไปการเรียนรู้ของ AI จะมีมาตรวัดมาตรฐานสองอย่างคือ Training loss และ Validation loss (จะอธิบายอย่างละเอียดใน ThaiAGI SuperSeries 2025) ซึ่งโดยหลัก คือ สองตัวเลขนี้ยิ่งน้อย ยิ่งน่าจะหมายถึง AI เข้าใจข้อมูลที่กำลังเรียนได้ดี
ทว่าในความเป็นจริงแล้ว มีหลายปัจจัยมาก ที่สองตัวเลขนี้จะ “หลอก” เราได้ นั่นคือ เราเข้าใจไปเองว่า AI เรียนรู้ได้ดี แต่พอเอาไปใช้งานจริงในภาคปฏิบัติกลับทำงานไม่ได้เรื่องเลย เนื่องด้วยสาเหตุหลายประการ เช่น “Overfitting”, “Anomaly Data” และ “Data Leakage”
ใน ThaiKeras เคยยกตัวอย่างปรากฎการณ์นี้ไว้หลายบทความ อาทิ เช่น
Too good to be true : สิ่งที่ต้องระวังเมื่อพบผลลัพธ์ที่แม่นยำผิดปกติจากโมเดล Machine Learning
Lab จาก MIT ปฏิวัติความเข้าใจเรื่อง “สิ่งที่ AI เห็น”
ปรากฏการณ์ "Clever Hans" บน NLP (หรือ Deep NLP ไม่ได้เก่งอย่างที่คิด)
หรือแม้แต่ระดับ ChatGPT ก็ยังมีปรากฏการณ์ที่เรียกว่า “Reward Hacking”17 ทำให้การเรียนรู้ของโมเดลเหล่านี้มีจุดอ่อนในการใช้งานปฏิบัติ
ดังนั้นถ้าจะให้มั่นใจว่าโมเดลเข้าใจข้อมูลอย่างแท้จริง ผู้สอน AI อย่างเราจำเป็นต้องเข้าใจเรื่องเหล่านี้ลึกซึ้งและออกแบบการสอนอย่างรัดกุม
(3C) เข้าใจสมการเป้าหมายการเรียนรู้
การเรียนรู้ของ AI จะเริ่มจาก “สมการเป้าหมาย” (Objective function หรือ Loss function18) ซึ่งในขณะที่โมเดลเรียนรู้ข้อมูล โมเดลจะพยายามผลิต output ให้สอดคล้องกับสมการเป้าหมายให้มากที่สุด นั่นคือ สมการเป้าหมายนี้ จะกำหนดทิศทางความฉลาดของโมเดลว่าควรจะวิ่งไปสู่จุดใด
จุดเริ่มต้นดีมีชัยไปกว่าครึ่ง ฉันใด การออกแบบสมการเป้าหมายที่ดี ก็นำไปสู่โมเดลที่ดี ฉันนั้น
ประโยชน์อีกอย่างคือทำให้เราปรับปรุงกระบวนการสอนได้มีประสิทธิภาพขึ้น เช่น สมการเป้าหมายในโมเดล ChatGPT ดั้งเดิม (RLHF - รูป 8 บน) ยังต้องมีการสร้างโมเดลย่อยมาคำนวนเป้าหมายทำให้การสอนนั้นต้องใช้ทรัพยากรสูง การเข้าใจสมการเป้าหมายอย่างลึกซึ้งยังนำไปสู่การดัดแปลงสมการเดิมของ RLHF ไปเป็น DPO (รูป 8 ล่าง) ทำให้ใช้ทรัพยากรการสอนน้อยลงอย่างมีนัยยะสำคัญ
(สำหรับสมการข้างล่าง เราจะมาค่อยๆ ทำความเข้าใจกันตั้งแต่พื้นฐานง่ายๆ ใน ThaiAGI SuperSeries ใครอยากเข้าใจถึงแก่น ค่อยๆ เดินทางไปพร้อมกับ ThaiAGI นะครับ)

ในหลายๆ ครั้งการออกแบบสมการเป้าหมายที่ดี จะนำไปสู่นวัตกรรมโมเดลใหม่ที่ปฏิวัติวงการได้ เช่น Variation Autoencoder และ Diffusion Model19 ที่นำมาสู่โมเดลที่สร้างรูประดับเหมือนจริง เช่น Midjourney เป็นต้น
และความเข้าใจในสมการเป้าหมายอย่างถึงแก่น จะนำไปสู่ความเข้าใจว่าโมเดลเรียนรู้จริงหรือไม่ในหัวข้อ (3B) และก็นำไปสู่ความเข้าใจในตัวโมเดลใน (3D)
(3D) เข้าใจแต่ละส่วนประกอบของโมเดล ทั้งสมการคณิตศาสตร์ และการเขียนโปรแกรม
ขั้นนี้แท้จริงแล้วเป็นบันไดไปสู่ Level-4 นั่นคือก่อนที่เราจะไปปรับปรุงโมเดลให้มีประสิทธิภาพสูงด้วยเทคนิคต่างๆ ใน Level-4 เราจำเป็นต้องเข้าใจส่วนประกอบขั้นพื้นฐานของโมเดลก่อน
ใน Series แรกของเราที่กำลังจะออกมาเราจะพาเพื่อนๆ ไปทำความเข้าใจส่วนประกอบของโมเดล Transformers (โมเดลที่อยู่ตรงกลางในรูปที่ 7) ซึ่งเป็นหัวใจสำคัญของโมเดลชื่อดังอย่าง ChatGPT-O1/3 หรือ DeepSeek-R1 อย่างถึงแก่น
Level 4: เทคนิคและสมการระดับสูง
การพัฒนาโมเดลระดับ ChatGPT-O1 หรือ DeepSeek-R1 นั้นได้ปรับปรุงโมเดล Transformers ขั้นพื้นฐานไปหลายจุด รวมทั้งเพิ่มกระบวนการเรียนรู้อีกหลายขั้น ดั่งแสดงในรปที่ 9
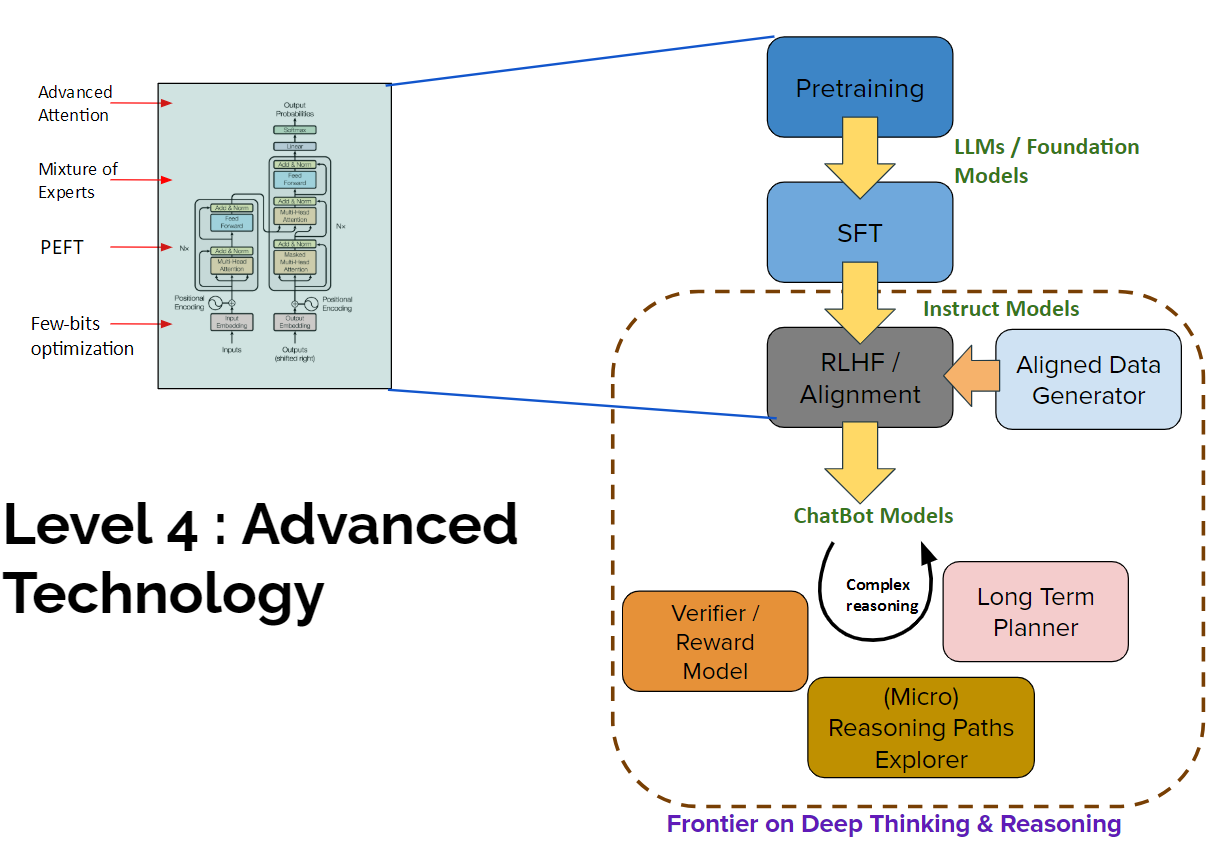
4A. การดัดแปลง Transformers เพื่อให้มีประสิทธิภาพมากขึ้น
ทำให้โมเดลเร็วขึ้น ประหยัดหน่วยความจำมากขึ้น ยกตัวอย่างเช่น
Advanced Attentions - Flash Attention, Latent Attention ดัดแปลงโมดูล Multi-head Attention โดย Flash Attention ให้ความเร็วมากขึ้นราว 3 เท่าและประหยัดหน่วยความจำได้ราว 20 เท่า
PEFT: Parameter Efficient Finetuning - ใช้เทคนิค Low-rank Matrix Approximation ซึ่งเป็นเทคนิคที่ทำให้ประหยัดหน่วยความจำในการสอนโมเดล AI ลงได้มากกว่า 90%
Few-bits optimization - โดยปกติโมเดล AI จะเก็บตัวแปรต่างๆ ทางคณิตศาสตร์จำนวนพันล้านถึงแสนล้านตัวแปรไว้ใน ตัวแปรจำนวนจริง (float) ซึ่งใช้หน่วยความจำ 32 bits แต่ด้วยเทคนิคมหัศจรรย์นี้ทำให้โมเดลสามารถเก็บตัวแปรส่วนใหญ่ไว้ใน float 8 bits หรือ 4 bits เท่านั้น ทำให้ประหยัดหน่วยความได้มากขึ้นอีก 75%
นอกจากนี้ยังมีเทคนิคอื่น เช่น Mixture-of-Experts ซึ่งสามารถใช้แทน Dense Layers ได้แต่มีความเร็วขึ้นอีกหลายเท่าตัว เมื่อเรารวมเทคนิคทั้งหมดนี้เข้าด้วยกัน ทำให้โมเดลใช้หน่วยความจำน้อยอย่างไม่น่าเชื่อและทำให้คนทั่วไปก็สามารถใช้งานโมเดลเหล่านี้ได้
เช่น โมเดล Phi-4 มีตัวแปรราว 14,000 ล้านตัวแปร ที่โดยปกติต้องใช้ server ราคาหลายแสน แต่ด้วยเทคนิคข้างต้นสามารถรันได้ใน server ฟรี เช่น Colab หรือ Kaggle เป็นต้น
นอกจากนี้ สองเหตุผลนี้ทำให้โมเดลสามารถ process input ขนาดยักษ์ได้ ยกตัวอย่างเช่น Google Gemini สามารถให้ให้ผู้อ่านใส่ข้อมูลปริมาณมหาศาล (1 ล้าน tokens หรือประมาณ 750,000 คำ เทียบเท่ากับการใส่ textbook ราว 10 เล่ม) เป็นข้อมูลก่อนที่จะให้ ChatBot ตอบได้
สำหรับมือใหม่ที่เพิ่งเริ่มต้นศึกษาใน Level-3 นั้นสามารถเรียกใช้งานเทคนิคเหล่านี้ได้ด้วยการเขียนโปรแกรมเพียง 2-3 บรรทัด เนื่องจาก Library ชั้นนำอย่าง Huggingface หรือ Unsloth ได้ implement เทคนิคเหล่านี้ไว้ระดับมืออาชีพแล้ว
4B. การเรียนรู้แบบ Reinforcement Learning (RL) ใน Transformers
การเรียนรู้ด้วยวิธีปกติของโมเดล Transformers เป็นการเรียนรู้แต่งประโยคแบบมีฟังก์ชันเป้าหมาย (ที่เราพูดถึงในหัวข้อ 3C) เพื่อ “ทายให้แม่นทีละคำ” (สร้างประโยคด้วยการทาย “คำใหม่” ไปต่อท้ายประโยค วนลูปไปเรื่อยๆ จนกว่าคำตอบจะสมบูรณ์)
ซึ่งการแต่งประโยคด้วยฟังก์ชันเป้าหมาย “ทายแม่นทีละคำ” นี้ แม้ถ้าดูผิวเผินจะแต่งประโยคได้สวยงามแต่ถ้าอ่านจริงจัง มนุษย์ทั่วไปจะพบได้ว่า ความเป็นเหตุเป็นผล มักจะไม่ค่อยดีนัก
เทคนิค RL เป็นการสอนแบบมีเป้าหมายที่ยากขึ้นและทำให้ประโยคใกล้เคียงมนุษย์มากขึ้น โดยการนำ RL มาสอนโมเดลเช่น ChatBot จะถูกเรียกว่า RLHF (RL from Human Feedback) ซึ่งยังมีแตกแยกย่อยไปอีกหลายเทคนิค เช่น PPO, DPO, ORPO, GRPO และอื่นๆ (รูป 10)

4C การสังเคราะห์ข้อมูลคุณภาพสูง (Synthetic Aligned Data Generation)
อย่างที่เกริ่นใน Level-3 ว่าโมเดล AI จะฉลาดได้เกิดจากการเรียนรู้จากข้อมูลที่เราเตรียมให้ และควรเป็นข้อมูลคุณภาพสูง (มีเหตุผล ไม่กำกวม ไม่วกวน พูดสุภาพ เป็นต้น)
กว่าจะมาเป็นอย่างโมเดลระดับ ChatGPT ข้อมูลคุณภาพสูงนี้ถูกกรองมาจากข้อมูลในอินเตอร์เน็ตแทบทั้งโลก และถูกเรียนรู้มาจนหมดแล้ว เมื่อข้อมูลที่เรียนรู้หมด AI ก็ยากที่จะฉลาดขึ้นได้
หนึ่งในเทคนิคขั้นสูงใน Level-4 ก็คือ การสร้างข้อมูลคุณภาพสูงเหล่านี้จาก AI นั่นคือ เราสามารถกระตุ้นให้ AI ที่เก่งแล้วระดับหนึ่ง ลองใส่หัวข้อแปลกใหม่ และสร้างข้อมูลที่น้อยคนจะพูดถึง แต่ยังคงความคุณภาพที่ต้องการไว้ได้ (อาจต้องมีการสร้างโมเดล AI เสริมเพื่อควบคุมคุณภาพ)
เทคนิคการสังเคราะห์ข้อมูลได้ผลดีเป็นอย่างมาก และ DeepSeek-R1 ได้เปิดเผยว่าเป็นสาเหตุสำคัญที่ทำให้ความฉลาดของ DeepSeek ขึ้นมาเทียบเท่า ChatGPT-O120
เราโมเดลที่ผ่าน RLHF มาแล้ว ยังฉลาดพอที่จะสามารถสร้าง “data จำลอง” เพื่อ
และโมเดล AI ที่ผ่านการเรียนรู้มาจนตกผลึกเช่น ChatGPT-O1/3 หรือ DeepSeek-R1 จะสามารถคิดยาวๆ อย่างเป็นเหตุเป็นผลได้อย่างไม่น่าเชื่อ
4D Longterm-Planner & Reasoning Model
หัวใจสำคัญของโมเดลที่จะฉลาดได้ระดับมนุษย์หรือเก่งกว่า ก็คือ ต้องสามารถแก้ปัญหายากๆ ที่ต้องอาศัยการคิดหนัก คิดยาวๆ อย่างมีเหตุผลระดับสูงได้ (เช่นการแก้ไขโจทย์คณิตศาสตร์โอลิมปิก หรือโจทย์วิทยาศาสตร์ปริญญาเอก)
โมเดลระดับ ChatGPT-O1/3 เป็นโมเดลแรกที่แสดงความสามารถตรงนี้ได้ด้วยเทคนิค Test-time Compute (ที่ OpenAI ไม่ได้เปิดเผยรายละเอียด)
ส่วน DeepSeek-R1 เป็นโมเดลถัดมาที่สามารถให้เหตุผลได้ระดับใกล้เคียง O1 โดยใชัวิธีการเรียนรู้จาก 4B และ 4C เป็นหลัก ซึ่งเป็นจุดหมายหนึ่งของ ThaiAGI ที่จะมาอธิบายให้เพื่อนๆ ได้เข้าใจกันครับ
เป้าหมายของทุกบทความใน ThaiAGI คือช่วยทุกคนที่ต้องการพัฒนาตัวเองใน Level 3 และ Level 4 อย่างจริงจัง ด้วยการสอนแบบเดียวกันกับที่เราสอนในระดับมหาวิทยาลัย (แต่ย่อยมาให้เข้าถึงได้ง่ายโดยไม่มีค่าใช้จ่าย)
ส่วนการแชร์ความรู้ AI ใน Levels 1-2 จะอยู่ในเพจเดิมคือ ThaiKeras & Kaggle หรือข่าวอื่นๆ ในวงการ AI ครับ
(หมายเหตุ: สำหรับ DeepSeek-R1 ที่จัดเป็น Level-4 แต่ถูกทำมาให้เราใช้สำเร็จรูปแล้ว เรายังสามารถนำ Agentic Framework ใน Level-2 มาพัฒนาให้ดีขึ้นไปได้อีก ดั่งเช่น ที่แสดงใน Open Deep Research)
Level 5: ระดับ The AI Star
Level-5 นี้เราหมายถึงนักวิจัยที่มีผลงานได้รับการยอมรับจากทั่วโลก เช่น ทีม OpenAI DeepMind Meta เป็นต้น เราพูดถึงระดับนี้เพื่อเป็นแรงบันดาลใจให้เพื่อนๆ มีเป้าหมายที่ท้าทายและยิ่งใหญ่
ซึ่งถ้าเพื่อนๆ อยากติดตามงานของเหล่า Stars ในวงการ ตามได้ที่ OpenAI, DeepMind, Meta AI เป็นต้น โดยวันหนึ่งเราอาจมีทีมระดับนี้ในประเทศไทยก็เป็นได้
ถ้าผู้อ่านท่านใดอยากพ้ฒนาฝีมือตัวเองให้ไปถึง Level-5 ก็จำเป็นอย่างยิ่งที่จะต้องมีพื้นฐานใน Level-3 และ Level-4 ที่แน่นมากๆ ก็ขอเชิญออกเดินทางไปพร้อมกันกับเราใน ThaiAGI SuperSeries ที่จะสอนพื้นฐานและเนื้อหาใน Level-3 และ 4 อย่างถึงแก่นครับ
แผนของ ThaiAGI SuperSeries ตั้งใจจะออกบทความราวๆ ทุกๆ 3 สัปดาห์
Series แรก Transformers (เนื้อหาที่เตรียมเกือบครบถ้วนแล้ว บางส่วนจะนำไปสอนระดับมหาวิทยาลัย)
Series สอง Reinforcement Learning (เนื้อหาที่เตรียมเกือบเตรียมครบ และได้นำไปทดลองสอนในระดับมหาวิทยาลัยเรียบร้อยแล้ว)
Series สาม Advanced AI Technology (กำลังศึกษาจัดเรียงลำดับ)
เทคโนโลยีสร้าง Video ยังถือว่าใหม่มาก และยังไม่มีโปรแกรมให้ใช้ฟรีมากนัก ทว่าสามารถลองเล่นและดูการจัดลำดับความสามารถของโมเดลต่างๆ ได้ที่นี่ครับ
ดูตัวอย่างอลิสาเพิ่มที่ https://alisamaid.com/docs/ai-chatbot-task/
ตัวอย่างการใช้งาน Google Gemini API ด้วยภาษา Python เบื้องต้นดูที่นี่ครับ (การใช้งาน API ของโมเดลอื่นๆ ก็จะคล้ายกันสามารถค้นดูได้ที่ API manual ของแต่ละผู้ให้บริการ)
ดู 2 Tutorials จากทีม CrewAI ได้ฟรี คลิกที่นี่ Tutorial-1 และ Tutorial-2
สำหรับ hardcore programmer อาจจะชอบ DSPy ซึ่งอนุญาตให้เราควบคุมพฤติกรรมของแต่ละ Agent ได้อย่างละเอียดกว่า Framework อื่น นอกจากนี้ดู Agent Frameworks ที่น่าสนใจอื่นๆ ได้ที่บทความนี้ครับ
Agentic Programming Framework จะอำนวยความสะดวกเรื่อง Tool ให้เรียกใช้ง่ายๆ ไว้แล้ว เช่น คู่มือการใช้ Tools ของ CrewAI ดูได้ที่นี่ครับ
ดูรายละเอียดเสริมเรื่อง Vector Database ได้ที่ บทความเรื่อง “สร้าง ChatBot ที่คุยข้อมูลของเราเองได้” ของ ThaiKeras หรือติดตามได้ใน facebook page: fb.me/thaikeras ครับ
https://www.deeplearning.ai/the-batch/how-agents-can-improve-llm-performance
เราอาจมองได้ว่าเป็นการบังคับให้ AI คิดยาวๆ (Long Thought) คล้ายกับ Reasoning AI สมัยใหม่เช่น ChatGPT-O1/3 หรือ DeepSeek R1 ที่จะต้องคิดยาว ก่อนที่จะตอบ เป็นต้น
อลิสา implement multi-agent ด้วยเทคนิคที่เรียกว่า AutoGPT ดูเพิ่มที่ https://alisamaid.com/enterprise/
ตัวอย่างที่เผยแพร่ในฐานข้อมูลของ https://esmatlas.com/ จาก Meta AI มีโปรตีนถึง 772 ล้านชนิด
บทความจาก ThaiKeras เรื่องการสอนให้ AI เรียนรู้ RNA และ เรียนรู้ small molecules
แม้โมเดล AI จะมีมากมายหลากหลายชนิด ทว่าในปัจจุบัน โมเดล Transformers ได้รับการยอมรับโมเดลสารพัดประโยชน์ที่สามารถรับและผลิตข้อมูลทั้ง ข้อความ รูปภาพ เสียง ฯลฯ
โมเดลอย่าง ChatGPT, Gemini, Lllama, Deepseek, etc. ล้วนแล้วแต่มี Transformers เป็นหัวใจ ดังนั้นใน ThaiAGI SuperSeries 2025 จะเจาะลึก Transformers เป็นอันดับแรก
ในปัจจุบัน โมเดล Transformers ถือว่าเป็นโมเดลสารพัดประโยชน์ที่สามารถรับและผลิตข้อมูลทั้ง ข้อความ รูปภาพ เสียง ฯลฯ ดังนั้นใน ThaiAGI เราจะพูดถึง Transformers เป็นหลัก อย่างไรก็ดีการ implementation Transformers ก็มีหลากหลายเพราะในแต่ละทีมชั้นนำก็มีรูปแบบการรับ input / output ที่ต่างกันออกไป
https://lilianweng.github.io/posts/2024-11-28-reward-hacking/
ชื่อ Loss function เป็นที่มาของ Training loss และ validation
R1 Technical Report : https://arxiv.org/abs/2501.12948