

ปฐมบท AGI: AI มาถึงจุดนี้ได้อย่างไร
จาก Linear Algebra ถึง ChatGPT-o3 ในปี 2025

AI : Artificial Intelligence —> เทคโนโลยี “ความฉลาดเทียม” ที่ถูกประดิษฐ์ขึ้น
AGI: General Version of AI —> ความฉลาดที่ประยุกต์เข้ากับงานได้หลากหลาย ไม่เจาะจงเฉพาะงานใดงานหนึ่ง
ในช่วงไม่กี่ปีที่ผ่านมา มนุษย์ได้สร้าง “เทคโนโลยี AI” อย่าง ChatGPT ที่เชี่ยวชาญ “ภาษามนุษย์” อย่างแตกฉานระดับที่สามารถทำโจทย์ปัญหาปริญญาเอกได้, เทคโนโลยี Diffusion ที่ “วาดรูปถ่ายและวิดิโอ” ระดับเหมือนจริง เทคโนโลยี AlphaGo ที่เอาชนะแชมป์โลกมนุษย์ใน" “เกมส์โกะ” ที่สุดซับซ้อน หรือกระทั่งเทคโนโลยี AlphaFold ที่อธิบายโครงสร้างโปรตีน 3 มิติที่มนุษย์ไม่สามารถทำได้มาเกือบ 70 ปี และคว้า Nobel Prize 2024 ได้สำเร็จ
วิวัฒนาการของเทคโนโลยี AI เหล่านี้ที่พัฒนาไปอย่างรวดเร็วใน 10 ปีที่ผ่านมานี้ถูกคิดค้นโดยมนุษยชาติได้อย่างไร เราจะเล่าให้ฟังในบทความนี้ครับ
ซึ่งจะเชื่อมโยงไปถึง Mini-Series ของ ThaiAGI ที่จะช่วยให้เพื่อนๆ ได้ศึกษา AI อย่างเป็นลำดับขั้นตอนและถึงแก่นแท้อีกด้วย

จริงๆ แล้วเทคโนโลยี AI ไม่ใช่สิ่งมหัศจรรย์เรื่องแรกที่เราสร้างขึ้น
มองย้อนในประวัติศาสตร์ของมนุษยชาติ จะเห็นว่ามนุษย์สร้างสิ่ง “เหลือเชื่อ” ที่ไม่เคยมีสิ่งมีชีวิตชนิดไหนทำได้มาก่อน (รูปที่ 2)
ราว 200 ปีก่อน เราสร้างเครื่องจักรกลขนาดยักษ์ที่แบกคนได้หลายร้อยคนที่เรียกว่า “รถไฟ” ซึ่งมาทดแทนและเหนือกว่า “ม้า” หลายร้อยตัว1
ราว 150 ปีก่อน เราสร้างแหล่ง “ผลิตพลังงาน” ขนาดยักษ์ที่เรียกว่า “โรงไฟฟ้า”2 ทำให้มนุษย์ไม่จำเป็นต้องพึ่งพาพลังงานจาก “ดวงอาทิตย์” และยังส่งพลังงานเหล่านี้ไปยัง “อุปกรณ์ไฟฟ้า” ที่ทำงานแทนมนุษย์สารพัด และทำให้ชีวิตมนุษย์สะดวกสบาย กินดีอยู่สบาย กว่าสิ่งมีชีวิตทุกชนิดในธรรมชาติ
ราว 100 ปีก่อน มนุษย์สร้าง “เครื่องจักรมีปีก” ที่สามารถ “เดินทางบนอากาศ” ได้เหมือนนก และสร้างวิวัฒนาการ “การบิน”3 ทำให้เราเดินทางข้ามทวีปได้เพียงเวลาไม่กี่ชั่วโมง
ราว 60 กว่าปีก่อน มนุษย์เดินทางออกนอกโลก ไปยังอวกาศได้สำเร็จ4
และการกำเนิดโมเดล AI เช่น ChatGPT จะเป็นอีกครั้งที่จะถูกบันทึกไว้ในประวัติศาสตร์ ว่า
เรากำลังอยู่ในยุคที่มีการค้นพบเทคโนโลยีที่ยิ่งใหญ่ที่สุด ระดับเดียวกับยุคที่พี่น้องตระกูลไรต์เพิ่งคิดค้น “การบิน” ได้สำเร็จเมื่อ 100 ปีก่อน

เทคโนโลยีที่ประดิษฐ์สิ่งที่ “ฉลาด“ ระดับสมองของมนุษย์
สิ่งประดิษฐ์ทั้งหลายที่กล่าวมาแม้นจะ “มหัศจรรย์” ทว่าทั้งหมดนั้นทำเพื่อชดเชยข้อจำกัดทาง “ร่างกาย” และเป็นการใช้ “พละกำลัง”
มนุษย์เรานั้นแท้จริงแล้วไม่ได้เด่นเรื่อง พละกำลังเหมือนสัตว์อื่นๆ จริงๆ แล้วเราเด่นเรื่อง “สมอง” ที่ “ชาญฉลาด” ต่างหาก
AI (Artificial Intelligence) หรือ “ปัญญาประดิษฐ์” คือสิ่งประดิษฐ์แรกในประวัติศาสตร์ของมนุษย์ที่มาแทน “สมอง” ของคนซึ่งเป็นแหล่งกำเนิด “ความฉลาด” ที่ก่อเกิดเทคโนโลยีมหัศจรรย์ที่เราเพิ่งกล่าวถึงไป เหล่านี้จะเกิดขึ้นไม่ได้ถ้าไม่มี “ความฉลาด” ของเผ่าพันธุ์มนุษย์
ความฉลาดของมนุษย์ทำให้เราคิดค้น “ภาษา” ทำให้ “ความรู้” ถูกถ่ายทอดผ่านภาษา รวมทั้งยังถูกสะสมจากการเขียนบันทึก ซึ่งทำให้เกิด “การเรียนรู้” ประสิทธิภาพสูงต่างจากสัตว์ประเภทอื่น ทำให้ “ความฉลาด” สามารถพัฒนาได้อย่างต่อเนื่องทำให้ มนุษย์สามารถแก้ปริศนาที่ซับซ้อนมากอย่างเหลือเชื่อได้ (รูปที่ 3)

นวัตกรรมของมนุษย์ล้วนมีรากฐานจาก “ทฤษฎี” และ “คณิตศาสตร์”
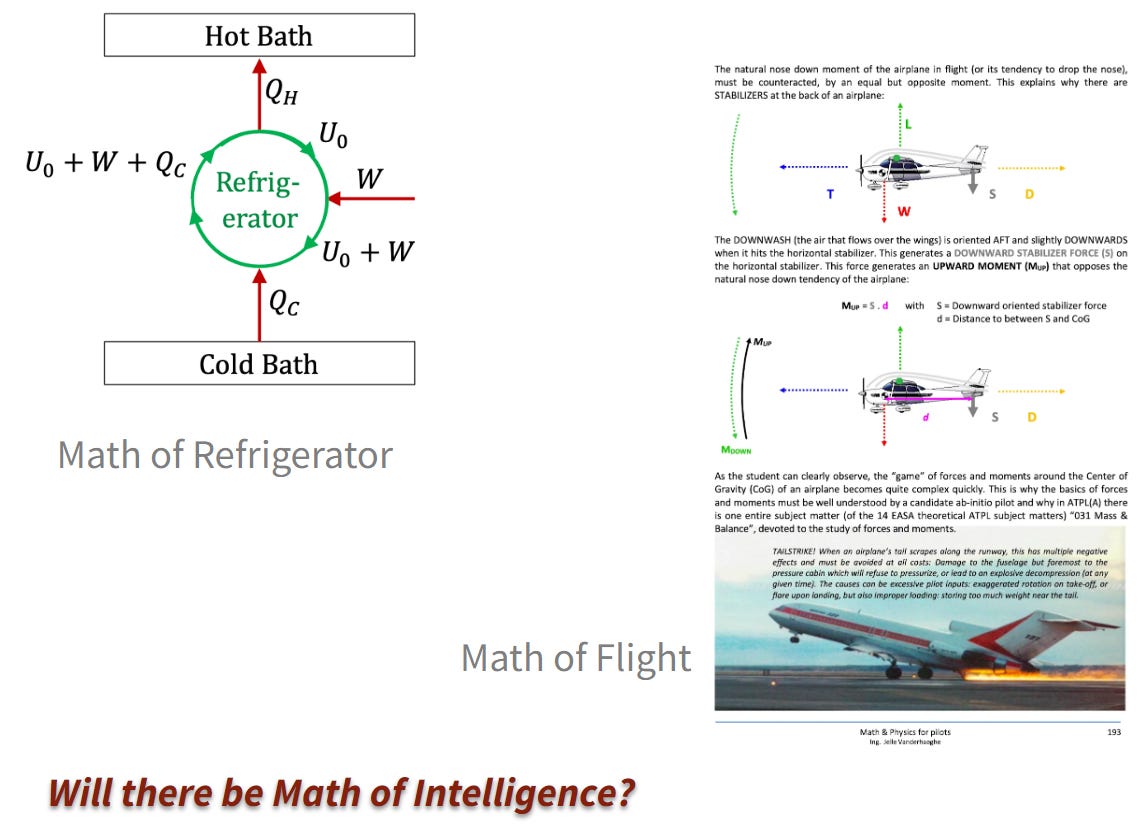
คณิตศาสตร์ของ “ความฉลาด” คืออะไร?
วิศวกร และนักวิทยาศาสตร์ทุกคนต่างได้รับการเรียนรู้และฝึกฝน “ทฤษฎีวิทยาศาสตร์” ที่มีพื้นฐานอยู่บนสมการ “คณิตศาสตร์” อย่างเข้มข้น เพราะนวัตกรรมทุกชิ้นล้วนอธิบายด้วย ภาษาคณิตศาสตร์ (รูปที่ 4)
คณิตศาสตร์เป็นภาษาที่ละเอียด รัดกุม ไม่กำกวม และเป็นภาษาที่ทรงพลังที่สุดที่มนุษย์คิดค้นขึ้น
การคิดค้นเทคโนโลยีอย่าง AI ที่มาถึงโมเดลระดับ AlphaGo, AlphaFold และ โมเดลที่ฉลาดที่สุดระดับ ChatGPT-o3 ล้วนมีต้นกำเนิดจากพลังของคณิตศาสตร์
ประวัติย่อของการพัฒนา AI ตั้งแต่คณิตศาสตร์ขั้นพื้นฐานจนถึงโมเดลสุดยอดที่กล่าวมาแสดงอย่างย่อในรูปที่ 5 ครับ
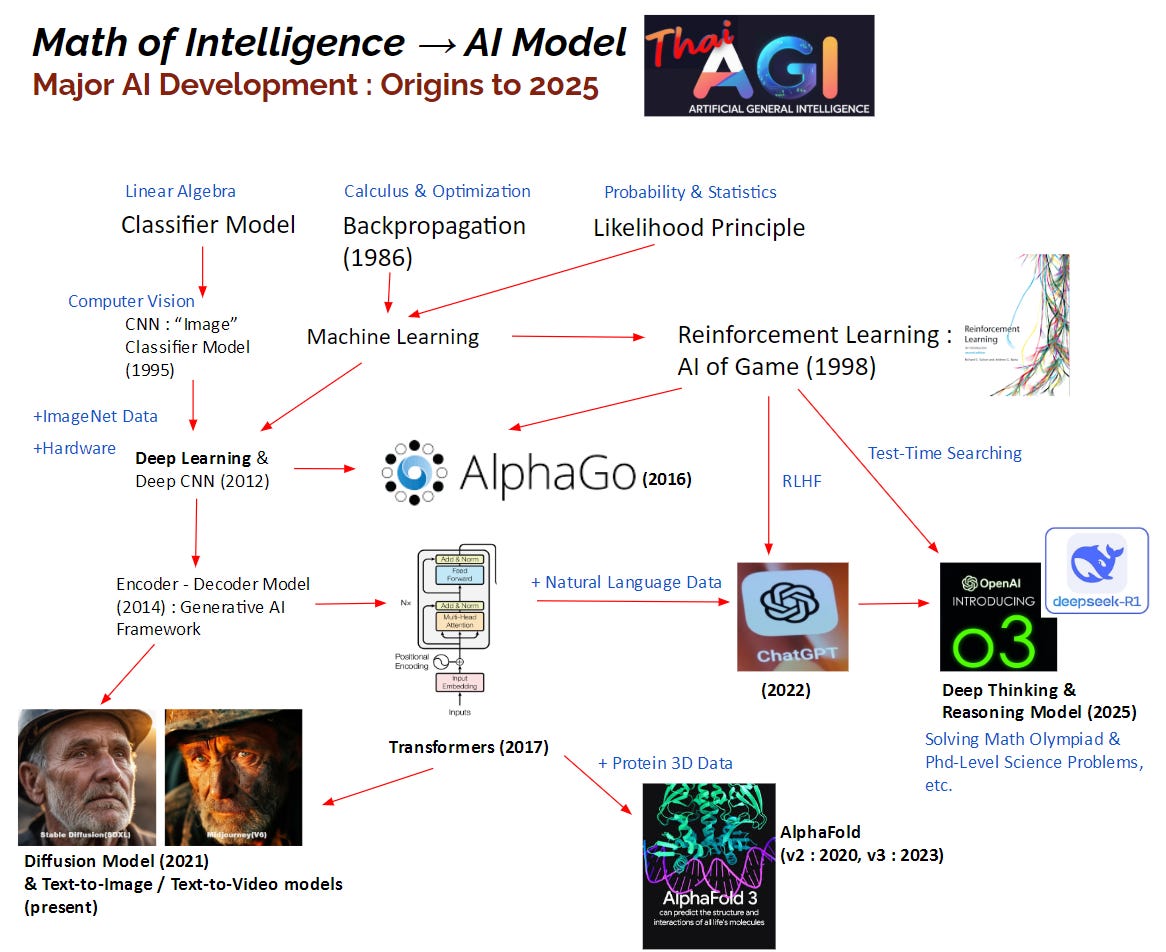
จาก Linear Algebra ถึง ChatGPT และ AlphaFold อย่างย่อ
หมายเหตุ เราจะอธิบายสมการคณิตศาสตร์อย่างละเอียดใน ThaiAGI Mini-Series ส่วนในบทความนี้เป็นการเล่าภาพรวม
เด็กๆ หลายคนตั้งคำถามว่าทำไมต้องเรียนแคลคูลัส (calculus) หรือสมการเส้นตรง เมทริกซ์ทั้งหลายในสมัยมัธยม ทว่าพลังของ Calculus และ Linear Algebra (เส้นตรง เมทริกซ์ ฯลฯ) นี่เองที่สร้างความฉลาดของ AI ในปัจจุบัน
รูปที่ 5 อธิบายว่านวัตกรรม AI ต่างๆ ถูกสร้างมาได้อย่างไร เห็นได้ว่ารากฐานสำคัญนั้นมาจากคณิตศาสตร์ 3 แขนงคือ calculus, linear algebra และทฤษฎีความน่าจะเป็น (Probability theory) แต่จุดกำเนิดแรกสุดที่เราจะพูดถึงคือ Linear Algebra
เชื่อหรือไม่ว่า ไอเดียของ AI แทบทั้งหมด มีจุดกำเนิดจากปัญหาง่ายๆ ที่เรียกได้ว่า ปัญหาจำแนกประเภท (Classification) แสดงดังรูปที่ 6 (บน) โจทย์คือ “ให้พิจารณาวัตถุที่กำหนด แล้วบอกว่าวัตถุนั้นจัดเป็นประเภทใด”5
ไอเดียของ AI แทบทั้งหมด มีจุดกำเนิดจากปัญหาง่ายๆ ที่เรียกได้ว่า ปัญหาจำแนกประเภท (Classification)
ตัวอย่างในรูปที่ 6 (บน) คือปัญหา classification ยุคแรกๆ หลายสิบปีก่อน ที่นักวิจัยพยายามพัฒนา AI ขึ้นมา นั่นคือการแยกดอกไม้ตระกูล Iris “สาม” สายพันธุ์ ซึ่งจากรูปเราจะเห็นว่าทั้งสามมีรูปร่างดอกที่คล้ายกันมาก
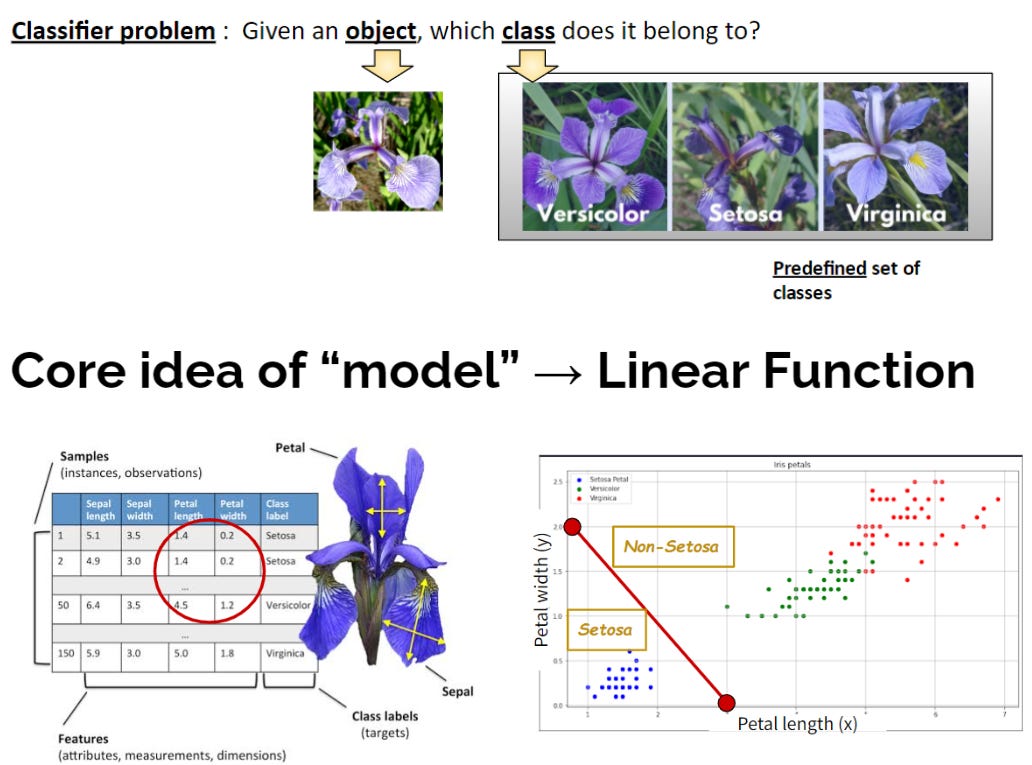
วิธีที่มนุษย์เราคิดขึ้นเพื่อแก้ปัญหานี้คือ การวัดความยาวและความกว้างของกลีบดอก แล้วนำมาพล็อตดังรูปที่ 6 (ล่าง)
ซึ่งเมื่อนำความกว้างและความยาวมา plot ในแกน x และ y แล้ว Iris ทั้งสามกลุ่มจะแบ่งแยกกันค่อนข้างชัดเจน
โดยจะเห็นว่าเราสามารถจำแนก Iris สายพันธุ์ Setosa ได้ด้วยการสร้างเส้นตรงสีแดงมาแบ่ง
นั่นคือ ความรู้ สมการเส้นตรง บนระนาบ xy ที่เรียนตอนมัธยมใช้แก้ปัญหานี้ได้!
ซึ่ง คณิตศาสตร์เชิงเส้น นี้ถ้าศึกษาต่อเชิงลึกจะอยู่ในวิชา Linear Algebra ซึ่งสามารถพัฒนาประยุกต์ต่อไปเป็นการสร้างเส้นโค้ง รูปทรงต่างๆ ได้ไม่จำกัด! 6
การสร้างเส้นตรงเพื่อแก้ปัญหา Classification อาจถือได้เป็นหนึ่งในโมเดล AI ยุคแรกสุด
และความจริงก็คือโมเดล AI สมัยใหม่ก็ยังอยู่บนพื้นฐานของ Linear Algebra นี่เอง
ไม่ว่าจะเป็นโมเดลที่ล้ำระดับ ChatGPT, AlphaGo และ AlphaFold ก็ยังใช้คณิตศาสตร์เหล่านี้เป็นฐาน! (อธิบายเพิ่มใน Series Transformers ซึ่งเป็นโมเดลฐานของโมเดลชื่อดังเหล่านี้ครับ)
ในรูปที่ 6 (ล่าง) สังเกตว่าการวัดความกว้างและความยาวของกลีบดอกเพื่อสร้างแก่น xy นั้นเกิดจากความรู้ของมนุษย์ นั่นคือ “มนุษย์” เป็นคน “คิดไอเดีย” ว่า Features สำคัญในปัญหานี้คือ ความกว้างและความยาวของกลีบ
และการพึ่งความรู้ของมนุษย์นี่เอง ทำให้งาน AI นั้นไม่พัฒนาเป็นเวลา “หลายสิบปี” เพราะในปัญหาที่ยากขึ้น เช่น การจำแนกดอกไม้ทุกชนิดบนโลก (ไม่เฉพาะ Iris) เราก็ไม่สามารถใช้ทริคความกว้าง ความยาวได้อีกต่อไป อาจต้องใช้ สี รูปร่างของกลีบ ลักษณะเกสร ฯลฯ ซึ่งซับซ้อนเกินกว่าที่มนุษย์เราจะคิด Features สำคัญทั้งหมดได้
ปัญหา Classification ที่ดูเรียบง่ายนี้ เป็นหัวใจของโมเดลอย่าง ChatGPT เพราะการแต่งประโยคนั้นมองได้เป็นการทายคำ “ทีละคำ” และในแต่ละคำก็ให้ทายให้ถูกว่าเป็นคำไหน (เหมือนกับการทายประเภทดอกไม้)
(อย่างไรก็ดีจวบกระทั่งงาน Transformers ในปี 2017 ยังไม่มีทีมวิจัยใดทำแนวคิดนี้ให้เป็นจริงได้สำเร็จ)
กลับมาที่รูปที่ 5 ในปี 1995 Yann LeCun (ปัจจุบันปี 2025 คือหัวหน้าสูงสุดฝ่าย AI ของ Meta ที่ปรึกษาที่ Mark Zuckerberg ให้ความเคารพมากที่สุด) ได้เสนอวิธีการสร้างโมเดล AI ที่สามารถ “เข้าใจรูปภาพ” ได้โดยไม่ต้องพึ่งความรู้ของมนุษย์ โมเดลนี้มีชื่อว่า Convolutional Neural Networks หรือ CNNs ซึ่งมีคณิตศาสตร์พื้นฐานจาก Linear Filter (มีพื้นมาจาก Linear Algebra เช่นกัน)
ถ้าเราข้ามเวลามาในช่วงปี 2012-2018 โมเดล CNN นี่เองที่จะเป็นโมเดลแรกที่สามารถจำแนกประเภทดอกไม้ทั้งโลกได้โดยไม่ต้องพี่งความรู้มนุษย์
อย่างไรก็ดีในปี 1995 โมเดล CNN นี้ยังไม่สามารถแสดงศักยภาพได้จริง เนื่องจากในสมัยก่อนนั้นยังไม่มีข้อมูลรูปภาพที่เยอะพอที่จะมาสอนโมเดล และเทคโลยีคอมพิวเตอร์ของเราก็ยังไม่เร็วและไม่มีหน่วยความจำมากพอสำหรับโมเดลขนาดใหญ่
ระหว่างปี 2009-2010 แลบที่ Stanford ริเริ่มสร้างฐานข้อมูลรูปภาพขนาดใหญ่จำนวน 1 ล้านรูปเพื่อเป็นข้อมูลสอนโมเดล ทว่ายังไม่มีโมเดลใดสามารถเรียนความรู้จากรูปทั้งหมดได้อย่างมีประสิทธิภาพ
จนกระทั่งในปี 2012 จุดเปลี่ยนสำคัญขั้นแรกก็มาถึง7 เมื่อลูกศิษย์สองคนของ Geoffrey Hinton (ผู้คว้า Nobel Prize สาขาฟิสิกส์ปี 2024 จากผลงาน AI) ได้ใช้เทคโนโลยี GPU เพื่อสร้างและสอน CNN ขนาดใหญ่ขึ้นได้เป็นครั้งแรก และโมเดล CNN เมื่อปี 1995 ของ LeCun นี่เองที่แสดงให้นักวิจัยทั่วโลกได้เห็นถึงพลังของโมเดล AI ขนาดใหญ่ ซึ่งมักเรียกว่า DeepLearning ซึ่งเรียนรู้และทำนายข้อมูลรูปภาพที่ Stanford เตรียมไว้นับล้านรูปอย่างแม่นยำมากระดับที่ไม่เคยมีใครทำได้ใกล้เคียงมาก่อน
และปี 2012 นี่เองนับเป็นครั้งแรกที่เราสร้างหรือประดิษฐ์ “ความฉลาด” ได้ในระดับที่มนุษย์ยอมรับ และไม่กี่ปีถัดมาเริ่มมีการประยุกต์ใช้งานจริง หลายด้าน เช่น ด้านการแพทย์ สามารถช่วยแพทย์ตรวจดูสิ่งผิดปกติในฟิล์ม X-Ray ปอดได้ เป็นต้น
จากจุดนี้เองทำให้นักวิจัยเก่งๆ และบริษัทใหญ่ทั่วโลกเริ่มหันมาสนใจ AI (ทว่าคนทั่วไป จะยังไม่ตื่นเต้นเท่าใดนัก ซึ่งต้องรอไปอีก 10ปี เมื่อมาถึงปี 2022 ที่ ChatGPT ได้เปิดตัวให้ “ทุกคน” ได้ใช้งาน)
หนึ่งในลูกศิษย์สองคนของ Hinton ที่ชุบชีวิต CNN ขึ้นมาใหม่ในปี 2012 มีชื่อว่า Ilya Sutskever ผู้ซึ่งจะไปเป็นหัวหน้าทีมวิจัย OpenAI ในอนาคต
ในปี 2014 Ilya ซึ่งเวลานั้นอยู่ที่ Google AI ได้ออกแบบโมเดลที่สำคัญมากๆ อีกหนึ่งโมเดลที่เรียกว่า “Encoder-Decoder Model”8 ซึ่งแบ่งโมเดลออกเป็นสองส่วน คือ ส่วนที่ใช้ถอดความรู้จากข้อมูล (Encoder) และส่วนทำนาย (Decoder)
ซึ่งแนวคิด Encoder-Decoder นั้น และยังเป็นรากฐานสำคัญของโมเดลในปัจจุบัน โดยเฉพาะโมเดลพลิกโลกจาก Google ที่ถูกคิดค้นขึ้นในปี 2017 ที่มีชื่อว่า Transformers ซึ่งเป็นโมเดลแรกที่ทำให้ AI เข้าใจได้ทั้ง ภาษา ข้อความ เสียง และรูปภาพ
โมเดลพลิกโลกจาก Google ที่ถูกคิดค้นขึ้นในปี 2017 ที่มีชื่อว่า Transformers ซึ่งเป็นโมเดลที่ทำให้ AI เข้าใจได้ทั้ง ภาษา ข้อความ เสียง และรูปภาพ
ในเวลาถัดมา Ilya ได้ขึ้นเป็นหัวหน้าทีมวิจัย OpenAI และร่วมกับนักวิจัยชั้นนำคนอื่นให้กำเนิดโมเดลตระกูล GPT (2018) GPT-2 (2019) GPT-3 (2020) รวมทั้ง ChatGPT ในปี 2022
ไม่เพียงใช้ภาษาได้อย่างคล่องแคล่วเท่านั้น ในปี 2024 นี่เอง ได้กำเนิด ChatGPT O-series (O1 และ O3) ซึ่งเป็นโมเดลแรกของโลกที่ให้เหตุผลได้ซับซ้อนมากใกล้เคียงมนุษย์ โดยมีการคิดย้อนกลับไปแก้ความคิดที่ผิดพลาดของตนเองได้
และเป็นโมเดลแรกที่ทำโจทย์ระดับปริญญาเอกได้!!9
นำมาสู่ Gemini Thinking Model ของ Google หรือ Grok3-reasoning ของ xAI และ Deepseek R1 จากจีน ซึ่งวิ่งตามแนวคิดของ O-series มาและเป็นข้าวใหญ่ในต้นปี 2025 นี้ครับซึ่งโมเดลเหล่านี้สามารถคิดเหตุผลได้ละเอียดระดับเดียวกับมนุษย์ที่ฉลาดที่สุด 10
โดยโมเดล Transformers ที่เป็นแก่นกลางของ ChatGPT และผองเพื่อนนั้น ยังเป็นหัวใจของโมเดล AlphaGo ที่ชนะแชมป์โลกโกะได้ และโมเดลAlphaFold จากทีม Google DeepMind ที่เป็นโมเดลแรกในโลกที่แก้ปัญหา 50 ปีของวงการชีววิทยา นั่นคือปัญหา การทำนายรูปร่าง 3 มิติของโปรตีน11 ซึ่งงานนี้ก็ได้รางวัล Nobel Prize 2024 สาขาเคมี (ส่วน Hinton ได้รางวัลในสาขา Physics)
ดังนั้นในการทำความเข้าใจ AI ทางทีมงาน ThaiAGI จึงเห็นตรงกันว่าต้องเข้าใจ Transformers ก่อนเป็นอันดับแรก
นอกจากนี้ที่เราเกริ่นไว้ว่าปัญหา Classification ง่ายๆ นั้นเป็นรากฐานสำคัญของ “ปัญหาความฉลาด” ทั้งหมด รวมทั้งความฉลาดในการใช้ภาษาแก้ปัญหาของ ChatGPT ซึ่งเรื่องเหล่านี้จะอธิบายใน mini-series แรกของ ThaiAGI ครับ
โมเดล AI เรียนรู้จากข้อมูลปริมาณมหาศาลได้อย่างไร : เวทย์แห่ง Calculus & Probability
Linear Algebra เป็นคณิตศาสตร์ที่ช่วยให้โมเดล AI สามารถสร้าง “สมการความคิด” (เช่น เส้นตรงที่แบ่งของ 2 ชนิดออกจากกันในรูปที่ 6) ได้ ทว่าในสมการต่างๆ นั้นล้วนมีตัวแปรที่เราไม่ทราบค่าอยู่ ยกตัวอย่างเช่น ย้อนกลับไปที่รูปที่ 6 (ล่าง) เราทราบดีว่าสมการเส้นตรง (หรือระนาบตรง) บนระนาบสองมิติ xy คือ
โดย x และ y เป็น input (ในตัวอย่างนี้คือ ความกว้างและยาวของกลีบ) ทว่าตัวแปร a, b และ c นั้นเราจะทราบได้อย่างไร โดย a, b และ c ที่มีค่าแตกต่างกัน ก็จะทำให้เส้นตรง (กรณี input มีสองตัวแปรคือ x และ y จริงๆ แล้วจะเป็น “แผ่น” หรือ “ระนาบ” ตรง — linear plane) นั้นอยู่ในตำแหน่งและมีทิศที่ต่างกัน ดังแสดงในรูปที่ 8

ตัวแปรในสมการ เช่น a,b และ c นี้เรียกว่า parameters ของโมเดล ซึ่งกำหนดทิศทางและตำแหน่งของระนาบ รวมทั้งค่า output ด้วย
ในปัญหา Iris Classification ในรูปที่ 6 เราต้องการหาระนาบตรงที่ เมื่อจุด (x,y) ตกอยู่ในสายพันธุ์ Sentosa แล้ว สมการจะให้ค่า output เป็นบวก และถ้าจุด (x,y) ตกอยู่อีกฝั่งหนึ่งระนาบจะให้ output เป็นค่าลบเป็นต้น
ซึ่งการที่จะทราบได้ว่าระนาบใดที่จะให้ค่า output ที่ถูกต้องตามที่เราต้องการ (นั่นคือ parameters a,b,c ที่ให้ระนาบสอดคล้องกับข้อมูล) ย่อมต้องเรียนจากข้อมูลจำนวนมาก
การเรียน parameters ที่เหมาะสมกับข้อมูล ย่อมต้องเรียนจากข้อมูลจำนวนมาก
ศาสตร์ของการเรียนรู้โมเดล AI มีชื่อว่า Machine Learning ซึ่งสามารถสรุปขั้นตอนหลักได้ 2 ขั้นก็คือ
สร้างสมการ “เป้าหมาย” (objective function) ที่เราต้องการเรียน
สมการเป้าหมายนี้จะนิยามเพื่อให้ พารามิเตอร์ของโมเดลสอดคล้องกับข้อมูลสอน
ยิ่งพารามิเตอร์ (เช่น a,b,c ที่กำหนดเส้นของสมการในรูปที่ 6) สามารถแบ่งข้อมูลได้ดีเท่าไร สมการเป้าหมายยิ่งจะมีค่ามากขึ้น
หัวใจสำคัญของการสร้างสมการอยู่บน ทฤษฎีความน่าจะเป็นและสถิติ ด้วยหลักที่เรียกว่า Likelihood Principle ซึ่งเป็นจุดตั้งต้นของการเรียนรู้ของทุกโมเดล ไม่ว่าจะเป็น Diffusion, AlphaGo, AlphaFold, และ ChatGPT
หรือแม้แต่การเรียนรู้โมเดล Diffusion ซึ่งนำไปสู่ Midjourney และ Sora ซึ่งเป็นโมเดล AI ก้องโลกอีกกลุ่มที่สร้างภาพและวิดิโอได้สมจริง12 ก็อยู่บนหลักนี้เช่นกัน
แม้ว่าเแต่ละโมเดลจะมีสมการเป้าหมายต่างกันไป แต่ทั้งหมดจะยึดกับหลัก Likelihood Principle ซึ่งใน mini-series ของเราจะมาดูกันว่าสมการเหล่านี้มาได้อย่างไรกัน
สุ่มอ่านข้อมูลสอนเป็นชุดๆ และนำข้อมูลสอนนั้นมาอัพเดต parameters ทีละขั้น (parameter optimization) ตามสมการเป้าหมาย
ทุกครั้งที่อ่านข้อมูล พารามิเตอร์ก็จะถูกปรับตามทีละนิดๆ เพื่อให้สอดคล้องกับข้อมูลสอนมากขึ้นเรื่อยๆ และทำให้ ผลลัพธ์สุทธิในสมการเป้าหมาย นั้นดีขึ้นเรื่อยๆ
ทุกคนที่เรียน Calculus มาย่อมเคยผ่านบทเรียนที่ว่าการหาจุดสูงสุด (จุดที่ดีที่สุด) ของฟังก์ชันนั้นทำได้โดยการหาจุดที่ Derivative ของ function มีค่าเท่ากับ 0
ซึ่งหลักการพื้นฐานของ Calculus นี่เอง ได้นำมาสู่อัลกอริธึมที่เรียกว่า Backprogation ที่ใช้ในการอัพเดต parameters ของโมเดลทั้งหมดที่กล่าวข้างต้น โดยมีจุดประสงค์ที่จะค่อยๆ อัพเดต parameters จนกระทั่ง derivative ของ สมการเป้าหมายมีค่าใกล้ 013
อย่างไรก็ดี โมเดล AI ระดับ ChatGPT แม้จะเรียนด้วยข้อมูลมหาศาลระดับข้อความในเว็บทั้งโลก ด้วยหลักการนี้ แม้จะมีความเชี่ยวชาญด้านภาษามาก ใช้คำพูดได้สละสลวยรวมทั้งพูดได้หลายภาษา
ยังมีจุดอ่อนตรงที่ไม่สามารถมีเหตุผลได้ระดับเดียวกับมนุษย์ เนื่องจากเทคโนโลยี Machine Learning ที่อธิบายด้วย Likelihood Principle นั้นมีจุดอ่อนสำคัญนั่นคือ “สมการเป้าหมายที่เน้นการทำนายให้แม่นคำต่อคำ” (ทายทีละคำ)
การเรียนรู้โดยมีจุดประสงค์เพื่อทำนายทีละคำให้แม่นนี้ทำให้แม้ประโยคที่เขียนโดย AI จะดูสวยงาม แต่พอเราอ่านหลายๆ ประโยครวมๆ กัน เราพบว่าข้อความโดยรวมมักไม่เป็นเหตุเป็นผลมากพอ และหลายครั้งพูดวนไปมา ทำให้ในจุดนี้ AI ยังไม่สามารถให้เหตุผล ในปัญหาที่ซับซ้อนได้
นั่นคือ ในขั้นนี้ AI สามารถทำได้ดีในปัญหาขนาดเล็ก เช่น การแปลภาษา ประโยคต่อประโยค หรือการแต่งกลอนขนาดสั้น ทว่าการแต่งนิยายยาวๆ หรือโจทย์คณิตศาสตร์ยากๆ ที่ต้องการความเป็นเหตุเป็นผลขั้นสูง จะยังยากเกินไป
หลักการเรียนรู้ด้วย Likelihood Principle นั้นถูกนำมาใช้กับปัญหาอย่าง Classification มาหลายสิบปี ทว่า OpenAI เป็นทีมแรกที่ตระหนักว่า ต้องมี “การเรียนรู้ขั้นถัดไป” เพื่อให้ฉลาดขึ้น
OpenAI เป็นทีมแรกที่นำสุดยอดศาสตร์อีกหนึ่งแขนงที่เรียกว่า Reinforcement Learning (RL) มาใช้กับโมเดลตระกูล GPT ได้สำเร็จในปี 202214
RL เป็นศาสตร์ที่คิดค้นเพื่อมาให้ AI แก้สถานการณ์ที่ต้องมีการ “วางแผนที่ยาวขึ้น” และ OpenAI ได้นำเทคนิคของ RL มาใช้เรียนถัดจากการเรียนรู้ด้วย Likelihood Principle
Reinforcement Learning, AlphaGo, ChatGPT และ O-series & DeepSeek-R1
Reinforcement Learning (RL)15 คือศาสตร์และเทคนิคที่สอนให้ AI สามารถ “เรียนรู้” และ “คิด” บนสภาพแวดล้อมเสมือน (Simulated Environments)16
โจทย์ของ RL บนสภาพแวดล้อมเสมือนนี้กำหนดให้ AI ต้องทำนายหรือตัดสินใจหลายครั้ง ก่อนที่จะทราบว่าสิ่งที่ทำลงไปนั้นดีหรือไม่ ยากกว่าปัญหา classification ข้างต้น ที่จะทราบผลลัพธ์ว่าถูกหรือผิดทันทีในทุกๆ การทำนาย และเรียนรู้จากผลลัพธ์นั้นทันที (จุดนี้เราจะอธิบายอย่างละเอียดใน ThaiAGI series)
ตัวอย่างต่อไปนี้คือสภาพแวดล้อมเสมือนในมุมมอง RL ทีนิยมนำมาสอน AI
เกมส์ เช่น Mario, Street Fighters, Puzzles ต่างๆ หรือเกมส์กระดานอย่างหมากรุก หรือโกะ ต้องมี actions หรือเดินหมากหลายรอบ ก่อนจะทราบว่าชนะหรือแพ้
การขับรถ เครื่องบิน ควบคุมโดรน ก็ต้องผ่านการควบคุมหลายขั้นตอนก่อนที่จะทราบว่าจะเดินทางไปถึงเป้าหมายหรือไม่ (หรือ “ชน” และ “พัง” ไปก่อนจะถึงจุดหมาย)
ChatGPT เปลี่ยนมุมมองการแต่งประโยค ให้เป็นเหมือนการเล่นเกมส์ ที่ต้องมีการเลือกคำ หลายคำเป็น ไปสู่ คำตอบขนาดยาวที่สมบูรณ์ ถึงจะตัดสินได้ว่า ประโยคทั้งหมดดีหรือไม่ (ต่างจากการตัดสินทีละคำว่า “คำถัดไปดีไหม?” ในมุมมอง Classification + Likelihood Principle)
ปัญหา RL นั้นสอนยากกว่าปัญหา classification มาก ในทางปฏิบัติจึงสอน ChatGPT ด้วยมุมมอง classification ในหัวข้อที่แล้ว (ทำนาย คำต่อคำ) ให้เก่งก่อน (เรียกว่าขั้นตอน pretraining) แล้วนำโมเดลที่เก่งแล้วนั้นมาสอนต่อเพิ่มเติมด้วยแนวคิดของ RL17
แม้ขั้น pretraining จะสอนด้วยข้อมูลข้อความจากสื่อออนไลน์ทั้งโลก แต่ข้อความที่ปริมาณมหาศาลระดับนี้ย่อมมีประโยคไม่ดีและคุณภาพต่ำปะปนมามากมาย
ด้วยปริมาณที่มหาศาลของข้อมูล ทำให้ยากมากที่เราจะคัดออกกรองเว็บหรือข้อความคุณภาพต่ำ ซึ่งก็มีปริมาณมหาศาลเช่นกันออกจากฐานข้อมูล
เกมส์แต่งประโยคแบบ RL จะต้องมีการสร้าง “โมเดลให้คะแนน” (Reward Model) ขึ้นมาก่อน โดยจะเจาะจงคัดเลือกข้อมูลสอนโดยเน้นประโยคที่คุณภาพสูงในมุมมองของมนุษย์18
Reward Model ที่สร้างจากข้อมูลคุณภาพสูงจะไม่ให้คะแนน “คำต่อคำ” แต่จะให้คะแนน “ประโยคโดยรวม” ที่ (1) สมเหตุสมผล (2) เข้าใจง่าย (3) สุภาพ (4)ไม่มีเจตนาร้าย และ (5) ปลอดภัย (ทั้ง 5 คุณสมบัติ คัดเลือกโดยมนุษย์)
ซึ่งการนำ classification pretraining มาผสมกับ RL บน transformers ซึ่งนอกจากจะพูดจาคล่องเหมือนมนุษย์แล้วยังมีคุณสมบัติทั้ง 5 ข้อข้างต้น มนุษย์จึงได้ให้กำเนิดนวัตกรรมที่ชื่อว่า ChatGPT ในปี 2022
นอกจากนี้ในปี 2024 ทีม OpenAI ยังก้าวไปอีกขั้นด้วยการพัฒนา ขั้นตอนคิดหาคำตอบ (inference process) โดยใช้เทคนิคคิดล่วงหน้าลองผิดถูกหลายขั้น (เรียก Test-Time Computing) ก่อนที่จะตัดสินใจ action ในแต่ละขั้นด้วย
เทคนิคนี้ใช้ในการจินตนาการเดินหมากกับคู่แข่งก่อนจะเดินจริง ซึ่งเป็นส่วนสำคัญของ AlphaGo ที่ทำให้พิชิต Lee Se-Dol แชมป์โลก 18 สมัยได้ใน ปี 2016 ซึ่งเทคนิคคิดล่วงหน้านี้ไม่มีใน classification
และ OpenAI ในนำวิธีคล้ายกันนี้มาให้กำเนิด ChatGPT O-Series คือ O1 (2024) และ O3 (2025) เพื่อ AI สามารถคิดลองผิดลองถูกด้วยภาษามนุษย์ และกลับไปคิดใหม่ในจุดที่บกพร่องได้

เหตุการณ์ต้นปี 2025 ซึ่งคือเวลาปัจจุบันขณะผู้เขียนกำลังเขียนบทความนี้, ChatGPT และโมเดลคู่แข่งอย่าง Gemini, Grok และ DeepSeek กำลังพัฒนาเทคนิค Test-time compute ดังกล่าวร่วมกับ RL เพื่อไปสู่ โมเดล AI ที่มีความสามารถใน “การคิดระยะยาว” (Long Chain-of-Thought - Long CoT) เหมือนมนุษย์ที่มีการทดหลายหน้ากระดาษเพื่อ แก้ปัญหาที่ซับซ้อนขั้นสุด (hihgly complex problems) อาทิเช่น ปัญหาคณิตศาสตร์ระดับโอลิมปิก หรือปัญหาวิทยาศาสตร์ระดับปริญญาเอก เป็นต้น ซึ่งสร้างความตกตะลึงไปทั่วโลก19
โดยทีม ChatGPT ไม่มีการเปิดเผยรายละเอียดเทคโนโลยีเบื้องหลัง Long CoT ที่น่ามหัศจรรย์นี้ แต่ได้ใบ้เพียงเล็กน้อยว่าได้มีการใช้เทคนิค Test-time computing (ดูหัวข้อ RL ด้านบน) อย่างมีประสิทธิภาพ
หลังจาก ChatGPT ประกาศ O-series ไม่นานทีม Google Deepmind ก็ได้ตีพิมพ์งานวิจัยที่สนับสนุนเทคโนโลยี test-time compute นี้20 และ Google ได้ออกโมเดล Gemini Flash Thinking21 ที่คล้ายกับ O-series
ในวันที่ 20 มกราคม 2025 DeepSeek แลบเล็กๆ จากจีนได้สร้างความตื่นตะลึงให้โลก AI ด้วยการสร้าง DeepSeek R1 ที่มีความฉลาดระดับเดียวกับ ChatGPT-O1 แต่ใช้งบประหยัดกว่านับสิบเท่า รวมทั้งได้เปิดเผยวิธีการสอน รวมทั้งให้นักวิจัย และบุคคลทั่วไปนำโมเดลไปใช้ได้22
อนึ่ง ในรายงานของ DeepSeek นั้นดูเหมือนจะไม่ได้ใช้ Test-time computing โดยตรง ทว่านำ output ของโมเดลที่ผ่าน Test-time computing อย่างเช่น DeepSeek R1-lite23 ไปสอน DeepSeek-V324 แล้วนำ output V3 กลับมาสอน ตัว R1 อีกที (DeepSeek นั้นพัฒนามาหลายโมเดลอย่างต่อเนื่องและนำมาต่อยอดกัน ไม่เหมือนฝั่งตะวันตก ที่มักเริ่มสอนโมเดลใหม่จากศูนย์)
ซึ่งรายละเอียดในการสอน R1 ที่ชัดเจน ยังไม่ชัดเจนแม้ในกลุ่มนักวิจัยชั้นนำ25
เดือนกุมภาพันธ์ 2025 ทีม Grok xAI ของอีลอน มัสก์ก็ได้ออก Grok-3 ซึ่งมีประสิทธิภาพสู้หมัดต่อหมัดกับ ChatGPT-O3 ได้อย่างสมน้ำสมเนื้อ26
AI vs. AGI ต่างกันอย่างไร?
มาถึงจุดนี้หลายคนอาจจะมีคำถามว่า AI และ AGI แตกต่างกันอย่างไร
AGI คือการเติม G เข้าไปตรงกลางคำว่า AI โดย G ย่อมาจาก General ซึ่งหมายถึง “ความฉลาดแบบหลากหลาย” ประยุกต์ความฉลาดได้หลายงาน
แนวคิด AGI และ AI มีมาหลายสิบปีแล้วแต่ไม่เคยเกิดขึ้นจริง
ซึ่งโมเดล ChatGPT เป็นโมเดลแรก ที่ใกล้เคียงกับแนวคิด AGI นี้ ทั้งนี้เนื่องจาก โมเดล AI ทั้งหมดก่อน ChatGPT จะเก่งเพียงเรื่องใดเรื่องหนึ่งเท่านั้น (ความฉลาดแบบแคบ) เช่น
โมเดลจำแนกรูปภาพ บอกว่ารูปนี้ประกอบไปด้วยวัตถุอะไรบ้าง แต่ก็ไม่สามารถทำอย่างอื่นได้ เช่นตรวจโรคจากภาพ X-Ray ปอด
โมเดลตรวจโรคจากภาพ X-Ray ปอด ก็ไม่สามารถตรวจสอบวัตถุอื่นๆ ที่ไม่ใช่ภาพ X-Ray ได้
โมเดลที่ชนะแชมป์โลกโกะอย่าง AlphaGo ก็เล่นเกมส์อื่นๆ ไม่ได้ คุยกับมนุษย์ไม่ได้
โมเดล GPT ยุคแรกๆ ก็จะเก่งภาษาเฉพาะด้าน เช่น บางโมเดลเก่งแปลจากไทยมาอังกฤษ บางโมเดลเก่งแปลอังกฤษมาไทย บางโมเดลเก่งแต่งนิยาย แต่จะทำงานข้ามความถนัดไม่เก่ง
ChatGPT ที่ถูกสอนด้วยข้อมูลทั้งโลก รวมทั้งเทคนิคเพื่อให้พูดคุยทุกเรื่องผ่าน “ ภาษามนุษย์” ได้อย่างเป็นธรรมชาติ มีความเชี่ยวชาญด้านภาษาในหลากหลายมิติ ปรับพฤติกรรมผ่าน Reinforcement Learning และคิดละเอียดด้วย Test-time compute จึงเป็นโมเดลแรกที่เข้าใกล้ AGI แตกต่างจากโมเดล AI ในยุคก่อนๆ
ThaiAGI Super-Series
พูดกันง่ายๆ จุดประสงค์ของ ThaiAGI คือ พาผู้อ่านไปสู่ความเข้าใจทั้งภาคทฤษฎีและปฏิบัติกับเทคโนโลยีที่เป็นจุดเริ่มต้นของ AGI อย่าง O-series ที่ฉลาดระดับที่แก้โจทย์คณิตศาสตร์โอลิมปิคหรือโจทย์วิทยาศาสตร์ระดับปริญญาเอกได้
ซึ่งถ้าผู้อ่าน อ่านมาถึงจุดนี้ ก็จะเห็นว่าหัวใจของโมเดลเหล่านี้คือ Transformers (รูปที่ 5 และ รูปที่ 7) ซึ่งจะเป็น mini-series แรกของเรา
หลังจากนั้นเราจะมาเจาะลึก Reinforcement Learning ใน mini-series ที่ 2
จากนั้นเราจึงจะค่อยๆ เรียนรู้เทคโนโลยีระดับสูงบางอย่างที่เกี่ยวข้องแน่นอน เช่น Latent Attention, Group Relative Policy Optimization, Test-time Scaling ไปด้วยกัน
ซึ่งทั้งสอง series แรกเราได้เคยนำเนื้อหาบางส่วนสอนในระดับมหาวิทยาลัยมาแล้ว ทว่าเราไม่อยากให้ความรู้ถูกจำกัดเพียงนักเรียนกลุ่มเล็กๆ จึงตัดสินใจนำมาขยายเพิ่มเติมเป็น Super-Series สู่ ThaiAGI
แล้วพบกันเร็วๆ นี้ครับ
https://en.wikipedia.org/wiki/Steam_locomotive
https://www.powermag.com/history-of-power-the-evolution-of-the-electric-generation-industry/
https://en.wikipedia.org/wiki/Aviation_in_the_pioneer_era
https://www.nasa.gov/image-article/april-1961-first-human-entered-space
การแต่งประโยคของ ChatGPT แท้จริงแล้วก็ถูกมองเป็นการจำแนกประเภท โดย ChatGPT จะทำนาย “คำ” ถัดไปของประโยคที่กำหนด ทีละคำ สมมติคำศัพท์ทั้งหมดในภาษาอังกฤษมี 10,000 คำ โมเดล ChatGPT ก็คือโมเดลจำแนกประเภท “คำถัดไป” ว่าเป็นประเภทใดใน 10,000 ประเภทนั่นเอง
https://en.wikipedia.org/wiki/Basis_function
ประวัติช่วงปี 2010-2012 นี้อ่านเพิ่มเติมได้ในบทความนี้ของ ThaiKeras ครับ
ได้แนวคิดมาจาก Information theory
https://epoch.ai/data/ai-benchmarking-dashboard (เช่น GPQA Diamond dataset)
วัดจากโจทย์คณิตศาสตร์โอลิมปิก โจทย์เขียนโปรแกรม CodeForces และ ข้อสอบวิทยาศาสตร์ระดับปริญญาเอก : ดูบทความนี้ของ OpenAI
ปัญหาการทำนายรูปร่าง 3 มิติของโปรตีน ก็ยังมีรากฐานแนวคิดมาจากโมเดล Transformers ใน Classification problem ดูรายละเอียดใน Series นี้ของ Harvard
https://en.m.wikipedia.org/wiki/Diffusion_model
คีย์แมนหนึ่งในทีมวิจัยที่คิดค้น Backprogation เมื่อปี 1986 หรือราว 40 ปีก่อนและยังใช้จนถึงทุกวันนี้ก็คือ Geoffrey Hinton เจ้าของรางวัล Nobel Prize 2024 สาขาฟิสิกส์นั่นเอง
https://openai.com/index/instruction-following/
มหาคัมภีร์ของ RL คืองานเขียนของสองศาสตราจารย์ Sutton & Barto ในปี 1998 ที่ยังส่งอิทธิพลในทฤษฎี RL มาจวบจนปัจจุบัน สามารถ download 2nd-edition ที่ตีพิมพ์ปี 2018 ฟรี ที่นี่ : http://incompleteideas.net/book/the-book-2nd.html
RL พัฒนามาจาก “ทฤษฎีการควบคุม” (Control Theory) ในศาสตร์ของวิศวกรรมไฟฟ้า ซึ่งถ้าใครเรียนวิศวไฟฟ้า แล้วรู้จัก “สมการเบลล์แมน” สมการนี้จะยังเป็นหัวใจสำคัญของ RL อีกด้วย ซึ่งเราจะคุยกันในอนาคตใน Mini-Series RL ครับ
เกมส์แต่งประโยคของ ChatGPT ไม่ใช่สภาพแวดล้อมเสมือนแบบเกมส์อื่นๆ ที่สามารถให้คะแนนตอนจบเกมส์ได้ว่าแพ้หรือชนะ ดังนั้นทาง OpenAI จึงได้สร้างอีก “โมเดล” เรียกว่า Reward Model ขึ้นมาเพื่อให้คะแนนตอนจบเกมส์ (จบการแต่งประโยค) ดูเพิ่มที่ https://openai.com/index/chatgpt/
ตัวอย่างข้อมูลคุณภาพสูงที่สร้าง reward model ดูที่ https://huggingface.co/datasets/openbmb/UltraFeedback
https://openai.com/index/learning-to-reason-with-llms/
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters : https://arxiv.org/pdf/2408.03314
https://ai.google.dev/gemini-api/docs/thinking
ดู รายงาน ของ DeepSeek-R1 ณ เดือนมกราคม 2025 ซึ่งฉลาดใกล้เคียง ChatGPT-o1 ที่ฉลาดระดับที่แก้โจทย์คณิตศาสตร์โอลิมปิคหรือโจทย์วิทยาศาสตร์ระดับปริญญาเอกได้
https://api-docs.deepseek.com/news/news1120
https://api-docs.deepseek.com/news/news1226
Hugging Face Journal Club - DeepSeek R1 (youtube discussion video)
ดูการวิเคราะห์ Grok-3 ภาคปฏิบัติโดย Andrej Karphathy ที่นี่ https://x.com/karpathy/status/1891720635363254772